Organizations of all sizes are integrating large language models into their products, automating customer support, generating content, analyzing documents, and powering code assistants. But as AI adoption accelerates, so does a quiet and often overlooked cost center. For every prompt sent to a hosted model, every token generated, and every GPU-hour consumed running inference on self-hosted infrastructure, there is a cost. Left unmanaged, these costs can spiral quickly, transforming what started as a modest AI experiment into one of the most significant line items in an engineering budget.
AI costs today come from two fundamentally different sources. The first is the pay-per-token API economy, where organizations access powerful models from providers like OpenAI, Anthropic, and Google and are billed based on consumption. The second is self-hosted GPU infrastructure, where teams run their own models on dedicated or cloud-provisioned GPUs, trading variable API fees for fixed or reserved compute costs. Each model has distinct cost dynamics, distinct optimization levers, and distinct trade-offs. A mature AI FinOps strategy must address both.
This is precisely where FinOps principles, long applied to cloud infrastructure, must now extend to AI. Just as engineering teams learned to right-size EC2 instances and eliminate idle S3 buckets, they now need to apply the same rigor to model selection, prompt design, inference patterns, and GPU utilization. The good news is that AI costs are highly optimizable. With the right strategies and the right visibility, teams can cut spending dramatically without sacrificing quality.
Understanding How LLM API pricing Work
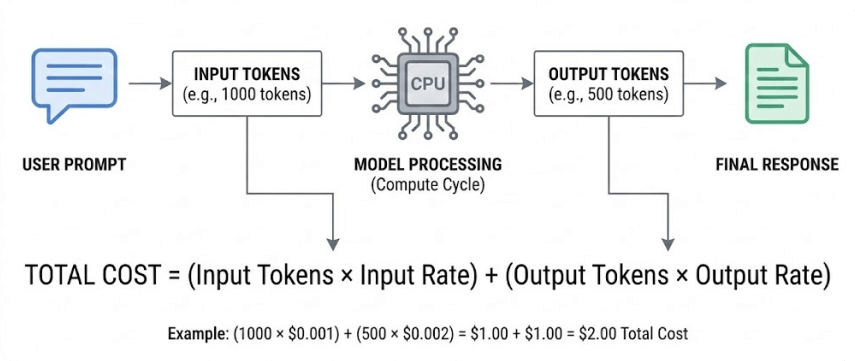
Most LLM providers bill on a per-token basis. A token is roughly four characters of text in English, meaning a thousand words costs approximately 750 tokens to process. Every API call involves two categories of tokens: input tokens — the content you send, including your system prompt, conversation history, and user message — and output tokens, the text the model generates in response. Output tokens are almost universally more expensive than input tokens, often by a factor of three to five.
This pricing structure immediately suggests where the waste hides: in long, redundant system prompts that get resent with every request; in verbose model outputs when concise answers would suffice; in the use of powerful, expensive models for tasks that simpler ones could handle just as well; and in the absence of caching, which forces identical inputs to be processed over and over at full price. A proper FinOps approach starts by mapping these cost drivers and quantifying their contribution to total spend.
LLM Prompt Compression: Paying Only for What Matters
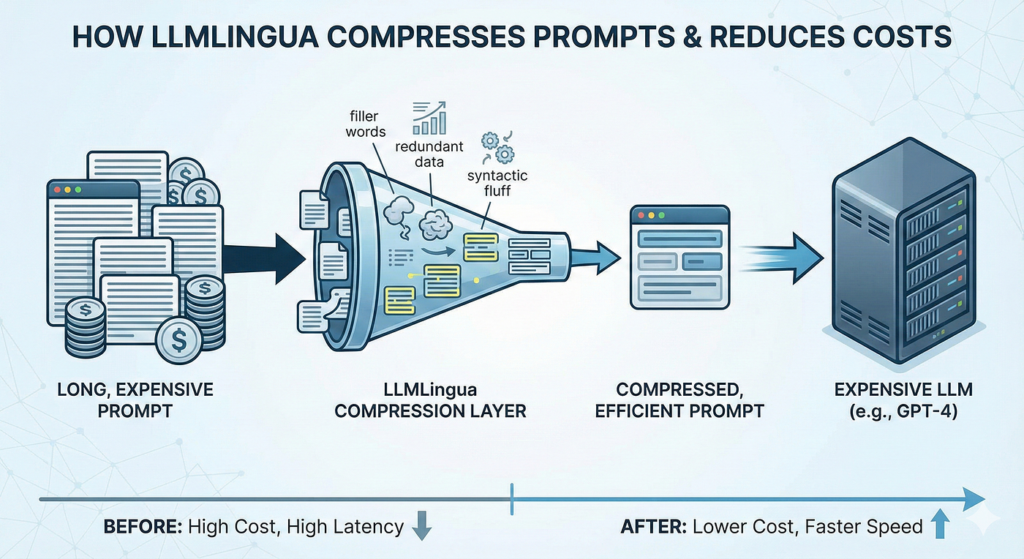
One of the fastest ways to reduce LLM API costs is to reduce the number of tokens sent in each request, a practice known as prompt compression. In many production systems, system prompts grow organically over time. Developers add instructions to correct edge cases, append examples to guide behavior, and include context that may only be relevant in rare situations. The result is a bloated prompt that inflates every single API call, even for the simplest queries.
Prompt compression involves systematically reviewing and tightening the language used in prompts — removing redundant instructions, replacing verbose explanations with concise directives, and stripping out examples that are no longer needed. Tools like LLMLingua can automate part of this process, removing tokens from long context documents while preserving the semantic meaning the model actually needs. Controlling output length is equally important: by instructing the model explicitly to be concise, or using max_tokens parameters to cap responses, teams can trim output costs significantly at scale.
Semantic Caching: Stop Paying for the Same Answer Twice
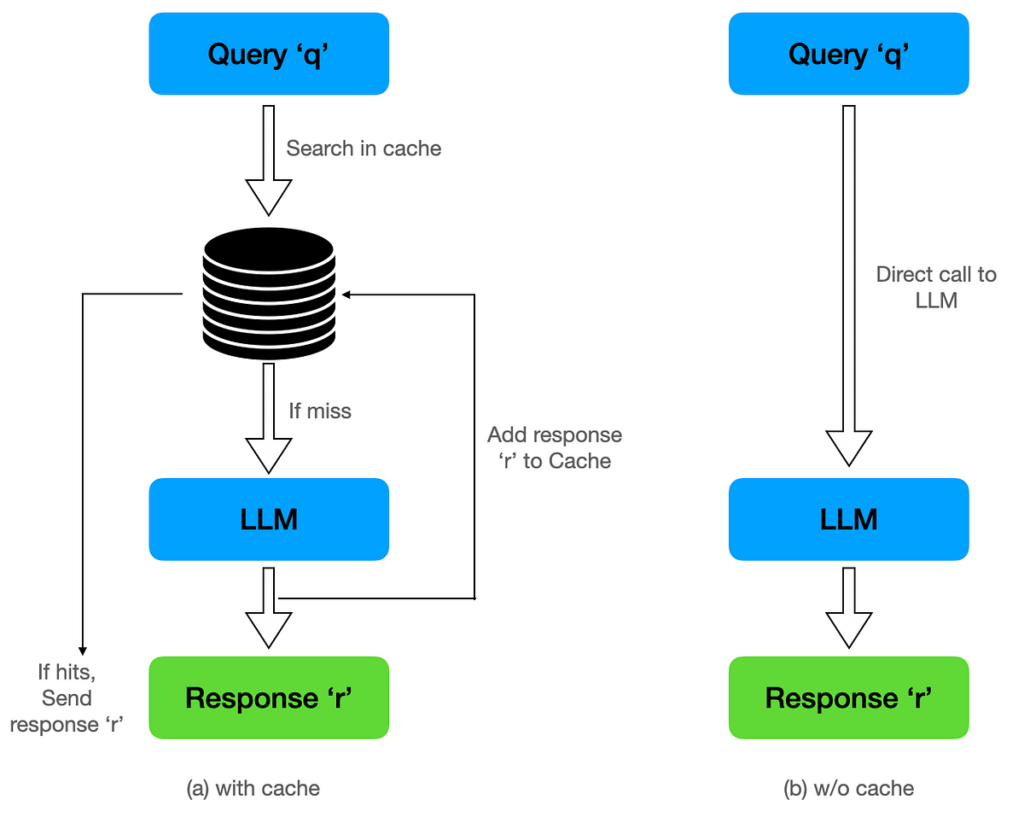
Caching is one of the most powerful and underutilized cost reduction strategies available to teams working with LLMs. Semantic caching takes traditional caching beyond exact string matching: incoming prompts are converted into vector embeddings and compared against a database of previously answered queries. If the new prompt is semantically similar — asking essentially the same thing in different words — the cached response is returned directly, without ever reaching the model. Tools like GPTCache and Redis with vector search can achieve cache hit rates of 30 to 60 percent for applications with high query overlap, such as customer support bots or internal knowledge assistants.
On the provider side, several API vendors now offer native prompt caching features. Anthropic’s Claude API supports prompt cache breakpoints that allow the model to reuse the KV cache for repeated system prompts or document prefixes. This means that even when the user’s question changes, the stable portion of the prompt is not reprocessed from scratch. For applications with large, constant context windows, this feature alone can cut input token costs by 80 to 90 percent.
LLM Batch Processing: Trading Latency for Savings
Not every AI workload needs to be real-time. When a team needs to classify thousands of support tickets, generate product descriptions for a catalog, or run nightly analysis on usage logs, there is no reason those tasks need to happen instantaneously. Batch processing — grouping multiple requests and submitting them through dedicated batch APIs — unlocks significant cost discounts. Both OpenAI and Anthropic offer batch APIs that process large volumes of requests asynchronously, with discounts of up to 50 percent compared to standard synchronous pricing. For organizations running regular large-scale inference jobs, shifting those workloads to batch processing is a straightforward way to halve the associated costs.
Model Selection: RightSizing Your AI Workloads
Perhaps the single biggest lever for reducing LLM API costs is model selection. The AI ecosystem now offers a wide spectrum of models — from frontier models like GPT-4o and Claude Opus to highly efficient smaller models like GPT-4o mini, Claude Haiku, Mistral Small, and open-source alternatives like Llama 3 and Phi-3. The price difference between tiers is enormous: a frontier model can cost 20 to 100 times more per token than a smaller purpose-built model. A disciplined routing layer — one that assesses the complexity of each incoming request and directs it to the appropriate model — can dramatically reduce costs without any degradation in quality for the vast majority of queries.
Running AI on GPUs: The Self-Hosting Equation
For organizations with sufficient scale, self-hosting open-source models on GPU infrastructure represents a fundamentally different cost model. Rather than paying a provider per token, teams provision their own compute — whether on-premises GPU servers or cloud GPU instances from AWS, GCP, or Azure — and absorb the fixed cost of running inference themselves. The economics can be compelling: running a fine-tuned Llama 3 70B model on a fleet of GPU instances can bring the effective cost per million tokens down by an order of magnitude compared to equivalent commercial APIs, while keeping data on-premises for compliance and privacy reasons.
However, GPU infrastructure introduces its own category of cost management challenges that mirror those of traditional cloud compute — but with higher stakes. GPU instances are among the most expensive resources in any cloud provider’s catalog. An A100 or H100 instance can cost anywhere from $3 to $10 per hour, and these costs accumulate relentlessly whether the GPU is actively processing requests or sitting idle. Unlike serverless API pricing, which scales to zero when unused, self-hosted GPU infrastructure demands discipline around scheduling, utilization, and lifecycle management.
GPU utilization is the central metric of self-hosted AI cost efficiency. A GPU running at 20 percent utilization is wasting 80 percent of its cost, and this is surprisingly common in teams that provision instances for peak load but serve average or low traffic most of the time. Optimizing GPU utilization starts with batching inference requests at the model serving layer — frameworks like vLLM, TGI (Text Generation Inference from Hugging Face), and Ray Serve are specifically designed to maximize throughput by processing multiple requests simultaneously using continuous batching techniques. With proper batching, a single GPU can serve many more concurrent requests than a naive single-request-at-a-time architecture would allow.
Model quantization is another critical optimization for GPU cost efficiency. Full-precision models (FP32 or BF16) consume significantly more GPU memory than quantized equivalents (INT8 or INT4), which means fewer model instances fit on a given GPU and throughput is limited. Techniques like GPTQ, AWQ, and GGUF quantization can reduce a model’s memory footprint by 50 to 75 percent with minimal quality degradation, enabling teams to run larger models on cheaper GPU hardware or fit more concurrent requests onto the same GPU. The savings from quantization compound significantly at scale: a workload that previously required four A100 instances might run on two after quantization, cutting infrastructure costs in half.
On the infrastructure procurement side, the same purchasing strategies that apply to general cloud compute apply — and matter even more — for GPU instances. Reserved instances and committed use discounts for GPU compute can reduce costs by 30 to 60 percent compared to on-demand pricing. For predictable baseline inference workloads, committing to reserved GPU capacity is almost always the right financial decision. For bursty or unpredictable workloads, spot or preemptible GPU instances offer deep discounts (up to 70 to 90 percent off on-demand) in exchange for the risk of interruption — a trade-off that is acceptable for batch inference jobs but not for latency-sensitive real-time serving.
Auto-scaling GPU clusters is technically more complex than scaling standard compute, but it is essential for cost efficiency. Clusters that scale down during off-peak hours and scale up to meet demand avoid the worst failure mode of GPU cost management: paying for idle capacity around the clock. Kubernetes-based GPU orchestration with custom metrics (requests per second, GPU memory utilization, queue depth) enables fine-grained auto-scaling policies that match compute supply to inference demand in near-real time.
LLM API vs. Self-Hosted: Choosing the Right Approach

The choice between managed API and self-hosted GPU infrastructure is not binary — most mature AI organizations use both. Managed APIs are ideal for getting to production quickly, for workloads with unpredictable or low volume, and for tasks that require the latest frontier model capabilities. Self-hosting makes economic sense when volume is high and predictable, when data privacy requirements restrict use of third-party APIs, or when a task can be adequately served by an open-source model that can be fine-tuned for the specific domain.
A useful rule of thumb: if your monthly API bill for a specific workload exceeds the cost of running equivalent GPU infrastructure, it is worth evaluating a migration. The break-even point depends on model requirements, expected utilization, and the engineering overhead of operating the infrastructure — but for many high-volume use cases, self-hosting crosses into better economics at surprisingly modest scale.
Tracking and Analyzing AI Costs Across Both Models
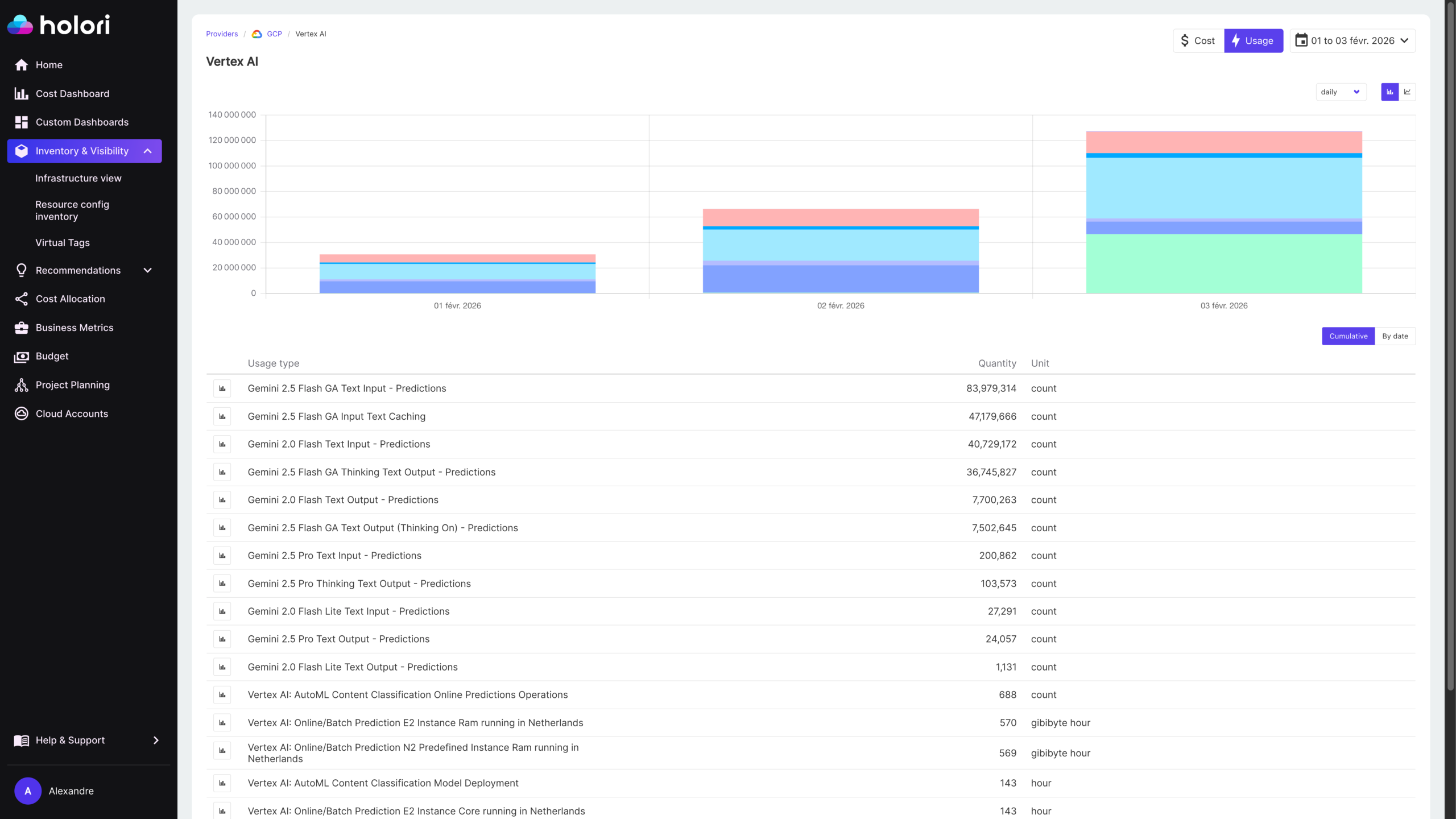
All of the optimization strategies above are only effective if you have the visibility to measure their impact. This is where FinOps tooling becomes indispensable. For API-based costs, most providers expose usage data through dashboards and APIs — but these native dashboards are typically limited to aggregate spend and lack the ability to attribute costs to specific features, teams, customers, or use cases. The solution is to instrument the application layer, logging every API call with metadata tags that identify the feature, team, or user segment responsible. This creates a rich dataset that enables meaningful cost attribution and trend analysis.

For self-hosted GPU infrastructure, cost tracking requires a different approach. The spend is visible in cloud billing as compute costs, but mapping those costs back to specific AI workloads, models, or teams requires tagging discipline and GPU-aware monitoring. Tools like DCGM (Data Center GPU Manager) and cloud-native GPU metrics provide utilization data at the hardware level, which can be correlated with workload metadata to understand the true cost of serving a specific model or feature. Without this correlation, GPU infrastructure appears as an opaque compute cost rather than an attributable AI expense.
Holori’s FinOps platform is designed precisely for this kind of unified, multi-dimensional cost visibility. As AI spending grows to span both managed APIs and self-hosted GPU infrastructure, Holori enables organizations to track all of it alongside their AWS, GCP, and Azure expenditure in a single view. Teams can set budgets per AI use case, define alerts that trigger when a specific model or feature exceeds its spending threshold, and analyze trends over time to identify which workloads are driving the most cost growth — whether that cost is coming from token fees or GPU hours. This unified perspective is critical: optimization decisions should be immediately visible in the spend dashboard, confirming that each change achieved its intended effect.
Beyond raw cost tracking, effective AI FinOps requires cost-per-outcome analysis. Knowing that you spent $8,000 on AI last month — split between API fees and GPU infrastructure — is useful, but knowing that each AI-generated support ticket resolution costs $0.12 on managed APIs versus $0.04 on self-hosted infrastructure is actionable. Building unit economics into your AI cost tracking framework transforms spending data from a historical report into a strategic decision-making tool.
Building a Culture of AI Cost Awareness
Technical optimizations are only part of the equation. Sustainable AI cost management also requires organizational alignment. Engineers building LLM-powered features need to understand the cost implications of their design decisions — both API-side choices like prompt length and model tier, and infrastructure-side choices like instance type and serving framework. Setting cost budgets per team, per product, and per experiment creates accountability. When teams know that their feature has a monthly AI budget and that overruns will be visible in a shared dashboard, they naturally build with cost in mind — the same shift in engineering culture that FinOps programs have successfully driven for cloud infrastructure.
Conclusion : How to optimize AI & LLM costs?
AI costs are not inevitable overhead — they are a manageable engineering and business problem. On the API side, prompt compression, semantic caching, batch processing, and intelligent model routing can reduce LLM spending by 50 to 80 percent. On the infrastructure side, GPU utilization optimization through inference batching and quantization, combined with smart procurement strategies like reserved instances and auto-scaling, can bring self-hosted inference costs in line with — or well below — equivalent API fees at scale.
But optimization without visibility is guesswork. The foundation of any serious AI cost strategy is measurement: knowing exactly what you are spending across both API fees and GPU infrastructure, attributing that spend to the teams and features responsible, and tracking the impact of every optimization decision. As AI costs grow to rival traditional cloud infrastructure costs for many organizations, FinOps platforms like Holori that can unify visibility across cloud and AI spending will become essential infrastructure in their own right. The organizations that build strong AI cost discipline now will be the ones that can scale their ambitions sustainably — without the budget surprises that catch unprepared teams off guard.

FAQ
Here are 5 questions that make sense given the article’s content:
What is the difference between LLM API costs and GPU infrastructure costs?
LLM API costs are variable and billed per token by providers like OpenAI or Anthropic. GPU infrastructure costs are fixed compute expenses incurred when running your own models on dedicated hardware. Both require different optimization strategies, but both need to be tracked and managed as part of a unified AI cost strategy.
When does it make financial sense to self-host a model instead of using an API?
The break-even point depends on your workload volume, model requirements, and tolerance for operational overhead. As a rule of thumb, if your monthly API bill for a specific workload consistently exceeds the cost of equivalent GPU infrastructure, it is worth evaluating a migration. For many high-volume use cases, self-hosting becomes more economical at a surprisingly modest scale.
What is semantic caching and how much can it save?
Semantic caching stores previous model responses and returns them when a new query is semantically similar, without ever calling the model again. Unlike exact-match caching, it handles rephrased questions and natural variation in user input. For applications with high query overlap, such as customer support bots, cache hit rates of 30 to 60 percent are achievable, translating directly into cost reduction.
Do smaller models actually produce acceptable results for production use cases?
For many tasks, yes. Classification, extraction, summarization, and translation are all well within the capability of smaller, cheaper models like Claude Haiku or GPT-4o mini. Frontier models are genuinely necessary for complex reasoning, nuanced generation, and tasks with high stakes. A routing layer that directs simple queries to smaller models and complex ones to frontier models is the most cost-effective architecture for most production systems.
How do you track AI costs across both APIs and GPU infrastructure in one place?
Native provider dashboards show aggregate API spend but lack workload-level attribution. GPU costs appear in cloud billing as generic compute. The solution is a FinOps platform like Holori that ingests cost data from both sources and allows teams to tag, attribute, and analyze AI spending by feature, team, or use case in a unified view, the same way cloud costs have been managed for years.