Cloud cost management at scale cannot rely on manual processes. Engineers are busy. Optimization recommendations sit in backlogs for weeks. The same idle instances appear in every monthly waste report without anyone acting on them. What worked at $500,000 in monthly cloud spend breaks down at $5 million.
FinOps automation is the answer to that scaling problem. But implementing it without the right foundation generates more noise than savings.
What Is FinOps Automation?

FinOps automation is the automated application of financial operations practices to cloud usage, combining policy, telemetry, and automated actions to control cost, allocation, and risk at scale. It is the practice of embedding financial guardrails directly into engineering workflows so that cost governance happens continuously, without requiring manual intervention at every step.
In practical terms, FinOps automation covers a wide spectrum of capabilities: alerting that fires when budgets are exceeded, policies that enforce tagging at provisioning time, schedules that stop non-production resources overnight, anomaly detection that routes unexpected cost spikes to the right owner, and AI agents that identify and eliminate waste autonomously. Not all of these are appropriate for every organization at every stage of maturity, and the order in which they are implemented matters as much as the capabilities themselves.
What FinOps automation is not is equally important to define. It is not a dashboard that shows cost data more clearly. It is not a reporting cadence that runs automatically. And it is not a single product you install and configure once. It is a set of policies, integrations, and workflows that evolve as your cloud environment and your FinOps practice mature.
Why Do You Need FinOps Automation?
The manual FinOps model has a ceiling. A FinOps analyst can review last month’s billing data, identify waste, write up a list of recommendations, and share it with engineering teams. Some of those recommendations get acted on. Most do not, because engineers have other priorities and the connection between a specific optimization action and the cost it saves is not always visible to the person who needs to take the action.
Without automation, FinOps depends on chasing spreadsheets and last-minute budget scrambles. Cloud environments move fast: new accounts spinning up daily, tags going missing, finance seeing a spike with nobody able to identify which resource caused it. The gap between identifying a cost problem and resolving it is where most cloud waste lives.
Automation closes that gap in three ways. It replaces recurring manual work (weekly waste audits, monthly tagging compliance checks, daily budget monitoring) with continuous automated processes that run without human effort. It reduces the time between identifying a problem and acting on it from days or weeks to hours or minutes. And it scales linearly with the size of the environment rather than requiring proportional growth in FinOps headcount as cloud spend increases.
Organizations that implement systematic FinOps automation consistently achieve 30 to 50% savings compared to unmanaged cloud spending, by continuously identifying and eliminating waste that manual processes miss between review cycles.
The organizations that need FinOps automation most are not necessarily the largest. Any team where optimization recommendations are not being acted on consistently, where the same waste items reappear month after month, or where the FinOps function is spending more time preparing reports than driving action, has already hit the ceiling of the manual model.
Prerequisite to FinOps automation
The prerequisites for effective FinOps automation are the same prerequisites for effective FinOps in general, just held to a higher standard because the consequences of acting on bad data are now automated rather than manual. Before building automation, three things need to be in place: billing data that is accurate and normalized, cost allocation that attributes at least 80% of spend to a specific owner, and tagging coverage that is high enough to make automated actions traceable to a responsible team.
Automating without robust telemetry or strong tagging causes wrong actions. Overly aggressive automated shutdowns impact service level objectives. And automation should never replace decisions that require human judgment, such as strategic procurement or architecture changes. Build the foundation first, then automate on top of it.
The FinOps Automation Maturity Ladder
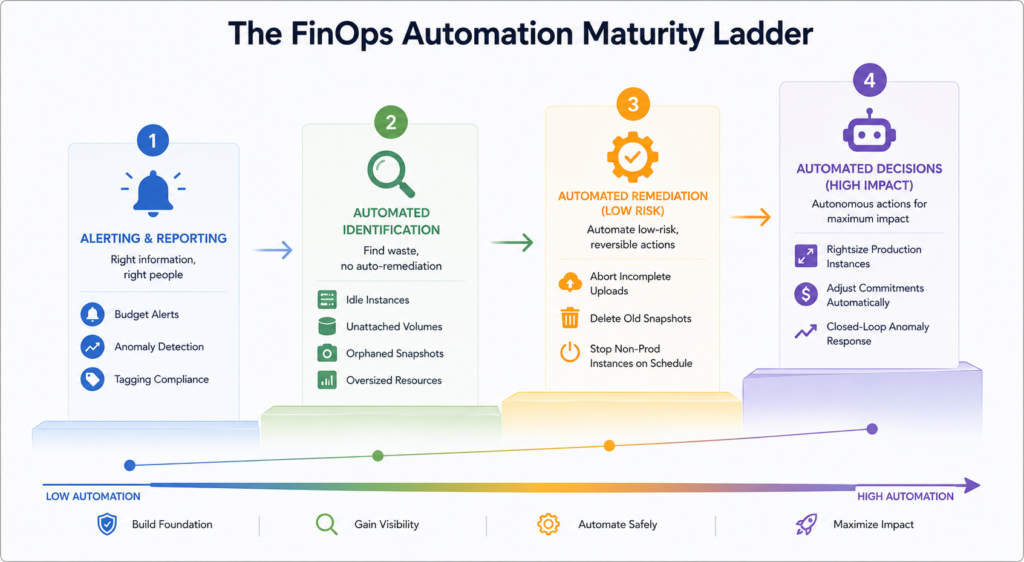
FinOps automation is not a binary state. It is a progression from fully manual to progressively more automated, with each stage building on the reliability of the previous one. Trying to skip stages is where most programs run into trouble.
At the earliest stage, automation is limited to alerting and reporting. Budget alerts fire when spend exceeds a threshold. Anomaly detection sends a notification when costs deviate unexpectedly. Tagging compliance reports run automatically on a schedule. No automated remediation happens, but the right information reaches the right people without manual effort. This stage is achievable by any team with a working FinOps platform and takes days to implement correctly.
The second stage introduces automated identification of waste without automated remediation. Scripts or platform policies run continuously to identify idle instances, unattached volumes, orphaned snapshots, and oversized resources, and generate a prioritized list of actions for engineers to review and approve. The human still makes the decision and executes the action, but the identification work that previously took hours per month now happens continuously and automatically.
The third stage introduces automated remediation for low-risk, well-defined actions. Incomplete multipart uploads are aborted automatically after seven days. Snapshots older than the defined retention window are deleted. Non-production instances are stopped on a schedule and restarted at the beginning of the next business day. These actions have a clearly defined scope, a low risk of impact on production workloads, and are reversible if something goes wrong. They are the right starting point for automated remediation.
The fourth and most advanced stage applies automation to higher-stakes decisions: automated rightsizing of production instances, automated commitment purchasing adjustments, and closed-loop anomaly response that can trigger scaling or cost containment actions without human approval. This stage requires the highest level of telemetry quality, the most mature tagging and ownership model, and the clearest escalation paths for when automated actions need to be reviewed or rolled back.
Automated Waste Detection and Remediation
Waste identification is the highest-value, lowest-risk starting point for FinOps automation. The categories of waste that are safe to automate early are those with a clear, unambiguous definition and a low probability of false positives.
Unattached storage volumes are the clearest example. A volume with no instance attachment and no recent access event is, by definition, not serving a workload. An automated policy that flags unattached volumes after 14 days of inactivity and deletes them after a 30-day review window (with a snapshot taken as a safety checkpoint) eliminates a consistent source of waste without any meaningful risk. The same logic applies to orphaned snapshots beyond the retention window, unattached Elastic IPs on AWS, and unattached public IP addresses on Azure and GCP.
Idle instance detection requires slightly more care because an instance that appears idle by CPU utilization may be performing memory-intensive or network-intensive work that CPU metrics alone do not capture. The automation should check multiple signals (CPU, memory, network, disk I/O) before flagging an instance as idle, and should route the flag to the instance owner for review rather than terminating automatically. The owner can then confirm the instance is genuinely idle or provide context that updates the detection rule.
Configure policies for automatic cleanup of unattached EBS volumes, obsolete snapshots, idle load balancers, and other waste. The policy continuously scans infrastructure, identifies resources matching defined criteria, and removes them automatically. What previously required manual tickets and engineering time now happens automatically.
Scheduled Resource Shutdown
Scheduled start and stop automation for non-production resources is one of the highest-return, lowest-risk FinOps automations available. A development or staging environment that runs 24 hours a day, seven days a week costs approximately three times what it costs running only during business hours on weekdays. Scheduling automation closes that gap without any engineering work and without affecting developer productivity.
The implementation differs by provider. On AWS, Instance Scheduler from the AWS Solutions Library handles start and stop scheduling for EC2 instances and RDS databases on a defined weekly schedule with support for time zone configuration. On Azure, Azure Automation runbooks handle scheduled start and stop for VMs and eligible database configurations. On GCP, Cloud Scheduler combined with Cloud Functions or direct API calls manages instance scheduling for Compute Engine and Cloud SQL.
The governance layer for scheduling automation is as important as the technical implementation. Teams need a clear process for requesting schedule exceptions (a production deployment that needs the staging environment available at an unusual hour), a way to temporarily override the schedule without disabling the policy entirely, and visibility into which environments are scheduled and what their current status is. Without these mechanisms, engineers work around the automation rather than with it, which generates both operational friction and unexpected costs when overrides are left in place permanently.
Policy-as-Code: Enforcing Cost Governance Before Resources Are Deployed
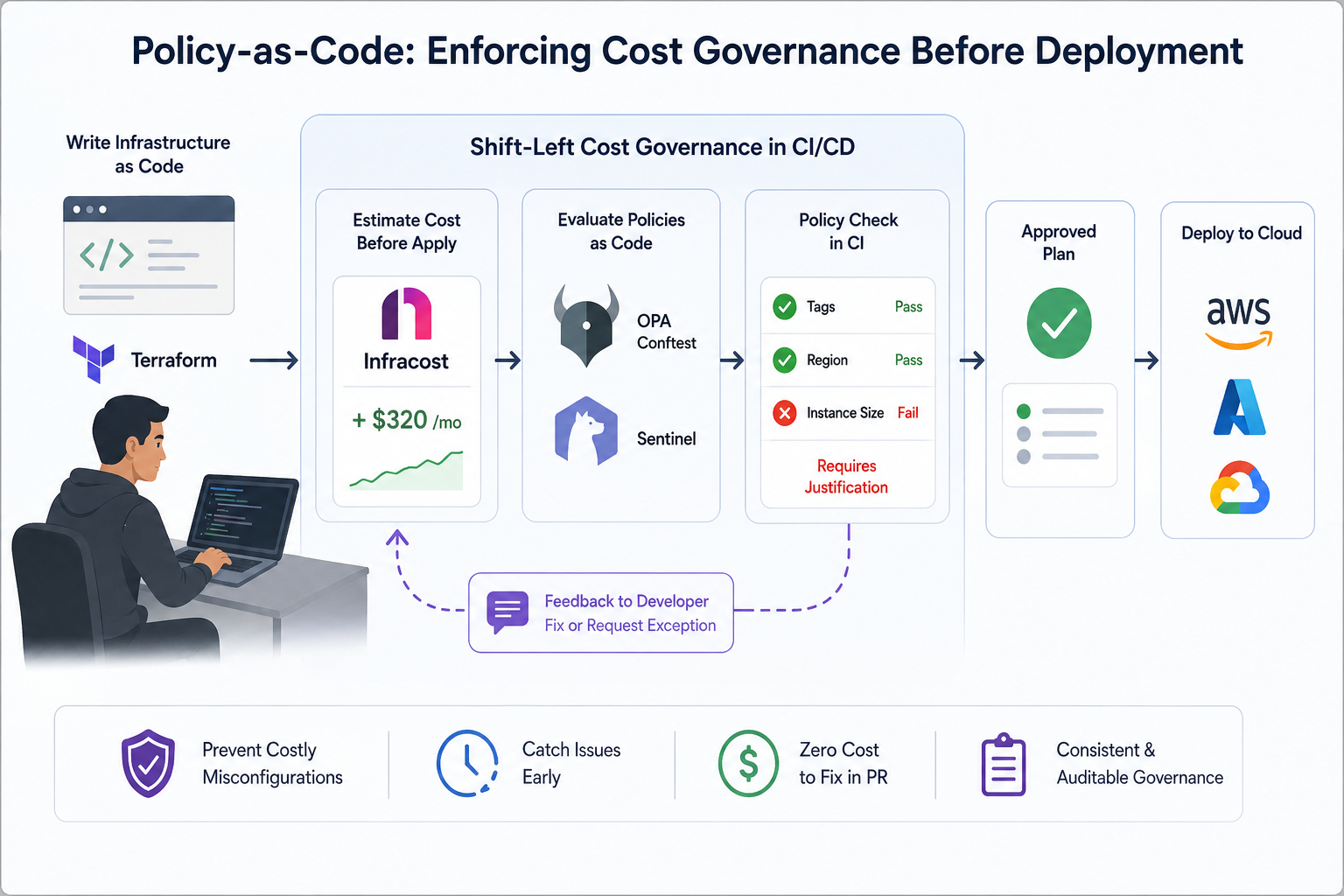
Policy-as-code is the mechanism that makes FinOps governance consistent and auditable rather than dependent on manual enforcement. Rather than documenting rules in a wiki that nobody reads, cost governance policies are expressed as code that runs automatically against every provisioning event and configuration change, enforcing governance at the point where it is most effective: before the resource exists and before the cost is incurred.
At the cloud provider level, native policy enforcement handles the last line of defense. AWS Organizations Service Control Policies can prevent resource creation in unapproved regions, block instance types above a defined size without an approval workflow, and require mandatory tags before provisioning completes. Azure Policy and GCP Organization Policy provide equivalent controls for their respective providers. These controls are valuable but they operate at deployment time, after the infrastructure code has already been written, reviewed, and approved.
The more powerful and earlier intervention happens at the Terraform level, before code ever reaches the cloud provider. Tools like Infracost integrate directly into Terraform workflows and calculate the estimated monthly cost of any infrastructure change before it is applied. A pull request that adds a new RDS cluster, increases an instance type, or enables Multi-AZ on a database automatically receives a cost estimate comment showing the expected monthly spend impact. Engineers see the cost consequence of their infrastructure decision at the same moment they are making it, not three weeks later when the bill arrives.
Open Policy Agent (OPA) with Conftest takes this further by allowing custom cost governance rules to be expressed as Rego policies and evaluated against Terraform plans in CI/CD pipelines. A policy that blocks any instance type above db.m6g.2xlarge without a tagged justification, flags any storage configuration above 500 GB without a retention policy, or warns when a new resource would push a team above a defined monthly spend threshold can run automatically on every pull request. The policy violation appears as a CI check failure with a clear explanation, giving the engineer the opportunity to adjust the configuration or request an exception before the change is merged.
Sentinel, HashiCorp’s policy framework for Terraform Cloud and Terraform Enterprise, provides the same capability in a managed form with a richer policy language and tighter integration with the Terraform workflow. Sentinel policies can enforce tagging requirements, restrict resource types and sizes by environment, and require cost estimates to be reviewed before plans above a defined threshold can be applied.
The combination of Infracost for cost visibility and OPA or Sentinel for policy enforcement creates a shift-left governance layer that catches cost problems at the cheapest possible point in the development cycle. A misconfigured resource that is caught in a pull request costs nothing to fix. The same misconfiguration caught in a monthly cost review costs whatever it spent between deployment and discovery, plus the engineering time to investigate and remediate it.
Anomaly Response Workflows
Anomaly detection without automated response is a notification system. Anomaly detection with automated response is a cost control system. The difference is whether the anomaly alert triggers a defined workflow or just an email that may or may not be acted on.
An effective anomaly response workflow has four components. Detection identifies the anomaly using statistical analysis of historical spend patterns, flagging deviations above a defined threshold (typically two to three standard deviations from the expected range). Enrichment adds context to the anomaly: which resource or service is responsible, which team owns it, what changed recently in that account or region. Routing sends the enriched alert to the specific person or team responsible for the resource, not to a generic FinOps inbox. Resolution tracks whether the anomaly was investigated, what the root cause was, and whether the spend was brought back within expected range.
Automating the enrichment and routing steps eliminates the manual investigation work that consumes significant time between when an anomaly is detected and when the right person knows about it. Rather than a FinOps analyst spending an hour cross-referencing billing data, asset inventory, and change logs to identify who owns the resource driving the anomaly, the automated workflow surfaces that context immediately alongside the alert.
Agentic FinOps: AI Agents That Take Action
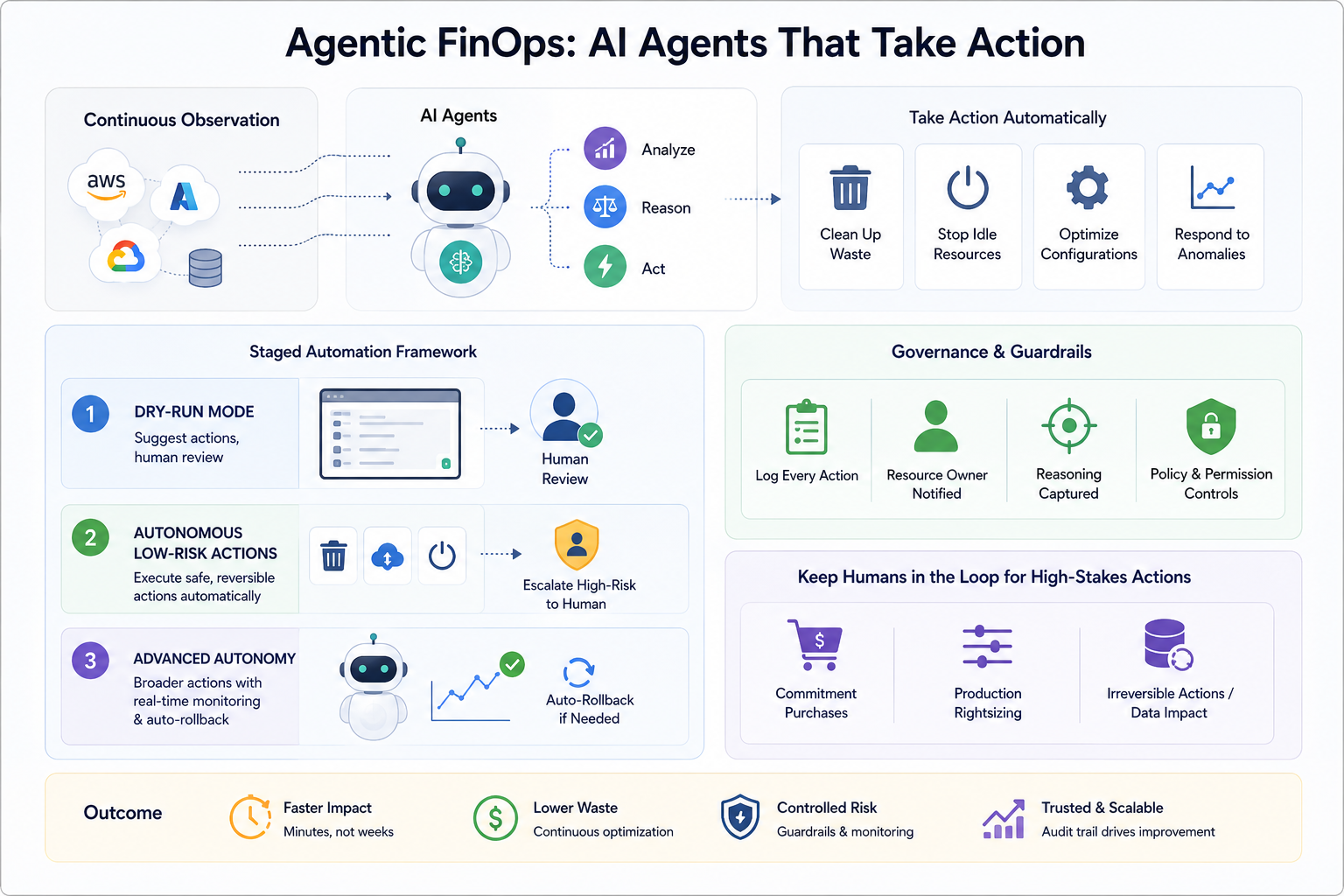
The next frontier of FinOps automation is not rule-based policies triggered by thresholds. It is AI agents that observe cloud environments continuously, reason about cost and efficiency trade-offs, and take autonomous actions without waiting for a human to review a recommendation and open a ticket.
Several platforms are already shipping this capability. Agents that automatically clean up unattached volumes, terminate idle instances, adjust autoscaling configurations, and respond to anomalies without human approval are moving from experimental to production-ready. The appeal is obvious: the gap between identifying a waste item and eliminating it collapses from days or weeks to minutes.
The risk is equally real. An agent that terminates an instance it classified as idle but that was actually serving a low-traffic internal tool creates an incident that costs more in engineer time to recover from than the savings justified. An agent that purchases a commitment based on a usage pattern that was about to change locks in waste rather than eliminating it. The autonomy that makes agentic FinOps powerful is also what makes it dangerous when applied without the right guardrails.
The practical framework for agentic FinOps mirrors the staged automation maturity described earlier in this guide, applied with AI capabilities at each level. At the lowest risk tier, agents operate in dry-run mode: they identify actions they would take and surface them for human review, building a track record of accuracy before any autonomous execution is enabled. At the intermediate tier, agents execute low-risk, reversible actions autonomously (deleting orphaned snapshots, aborting incomplete multipart uploads, stopping non-production instances on schedule) while routing higher-stakes decisions to a human approval workflow. At the advanced tier, agents handle a broader action set autonomously, with real-time monitoring of outcomes and automatic rollback if an action produces an unexpected result.
The governance layer matters as much as the AI capability itself. Every autonomous action taken by an agent should be logged with the reasoning that triggered it, the resource it affected, the owner of that resource, and the outcome. That audit trail is what makes agentic FinOps trustworthy rather than opaque, and what allows teams to tune agent behavior over time based on actual outcomes rather than theoretical accuracy rates.
Holori’s perspective is that human oversight remains essential for high-stakes, irreversible decisions: commitment purchases, production rightsizing, and any action that cannot be undone without a restore operation. For the large category of low-risk, reversible waste elimination actions, well-governed automation reduces the friction between insight and action that limits most FinOps programs at scale.
AI for Commitment Optimization
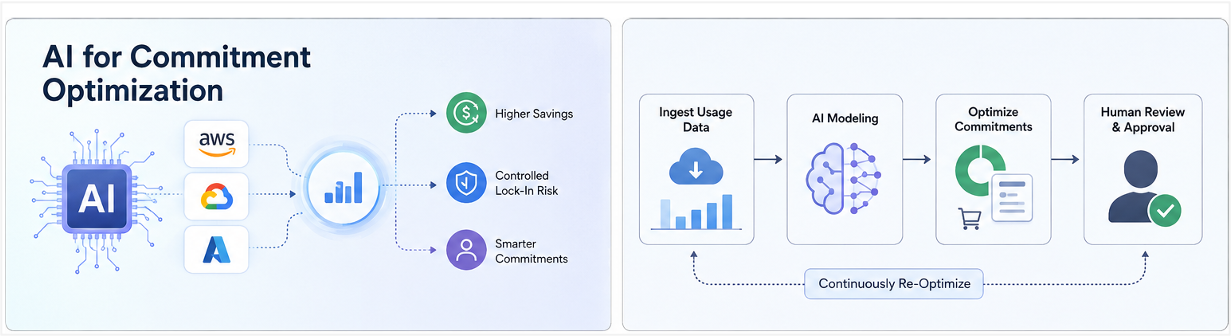
Commitment purchasing is one of the highest-value levers in cloud cost management and one of the hardest to get right. The decision of how much to commit, at which term length, across which instance families and regions, involves modeling future usage patterns that are genuinely uncertain. Undercommitting leaves savings on the table. Overcommitting generates waste that partially offsets the discount. Most teams manage this manually with spreadsheets and best guesses.
AI models significantly improve this decision by doing what humans cannot do efficiently at scale: ingesting months of usage data across hundreds of instance types and regions, identifying stable usage floors versus variable peaks, modeling the financial impact of different commitment configurations, and optimizing the blend of Reserved Instances, Savings Plans, and on-demand usage to maximize the Effective Savings Rate while keeping Commitment Lock-In Risk within acceptable bounds.
The important distinction from agentic automation is that AI-assisted commitment optimization is a recommendation system, not an autonomous execution system. The AI generates a purchasing recommendation with a clear explanation of the assumptions, the modeled savings, and the risk profile of the commitment. A human reviews and approves before any financial commitment is made. The AI removes the analytical burden of building that model manually. The human retains decision authority over a financial commitment that may run for one to three years.
The practical improvements over manual commitment management are substantial. AI models can reoptimize recommendations continuously as usage patterns change, rather than being updated quarterly when someone has time to rebuild the spreadsheet. They can model cross-provider commitment strategy simultaneously, identifying where an AWS Savings Plan commitment should be sized down to make room for a GCP Committed Use Discount that covers a growing workload. And they can quantify the trade-off between savings rate and lock-in risk explicitly, giving the human reviewer a clear basis for the approval decision rather than a single recommendation with no context about the alternatives.
What Not to Automate
The boundaries of FinOps automation are as important as its scope. Some decisions should remain with humans regardless of how mature the automation program becomes.
Commitment purchasing (Reserved Instances, Savings Plans, Committed Use Discounts) should not be fully automated without explicit human approval at the purchasing stage. The modeling can be automated and the recommendation generated automatically, but a financial commitment with a one or three year term and a meaningful dollar value warrants a human review before it is executed. The risk of an automated purchasing error (wrong instance type, wrong region, wrong term length) is high enough that the human checkpoint is worth the friction.
Production rightsizing should always involve the team that owns the workload before any change is made. An automated recommendation that a production database should be downsized is valuable. An automated action that downsizes a production database without engineering review is a potential incident. The automation should make the recommendation, route it to the owner with the supporting data, and track whether the action was taken, but not execute the change autonomously.
Finally, any action that cannot be reversed should require explicit human approval. Deleting a snapshot, terminating an instance, or removing a resource that cannot be restored from a backup are one-way doors. Automated identification is appropriate. Automated execution without review is not.
How Holori Supports FinOps Automation
Holori provides the visibility and data quality layer that makes FinOps automation reliable rather than risky. Anomaly detection operates across AWS, Azure, and GCP simultaneously, flagging unexpected cost movements in real time and enriching each alert with resource-level context from the asset inventory: what the resource is, who owns it based on tags or virtual tags, and what changed recently based on the diff diagram from the last daily sync.
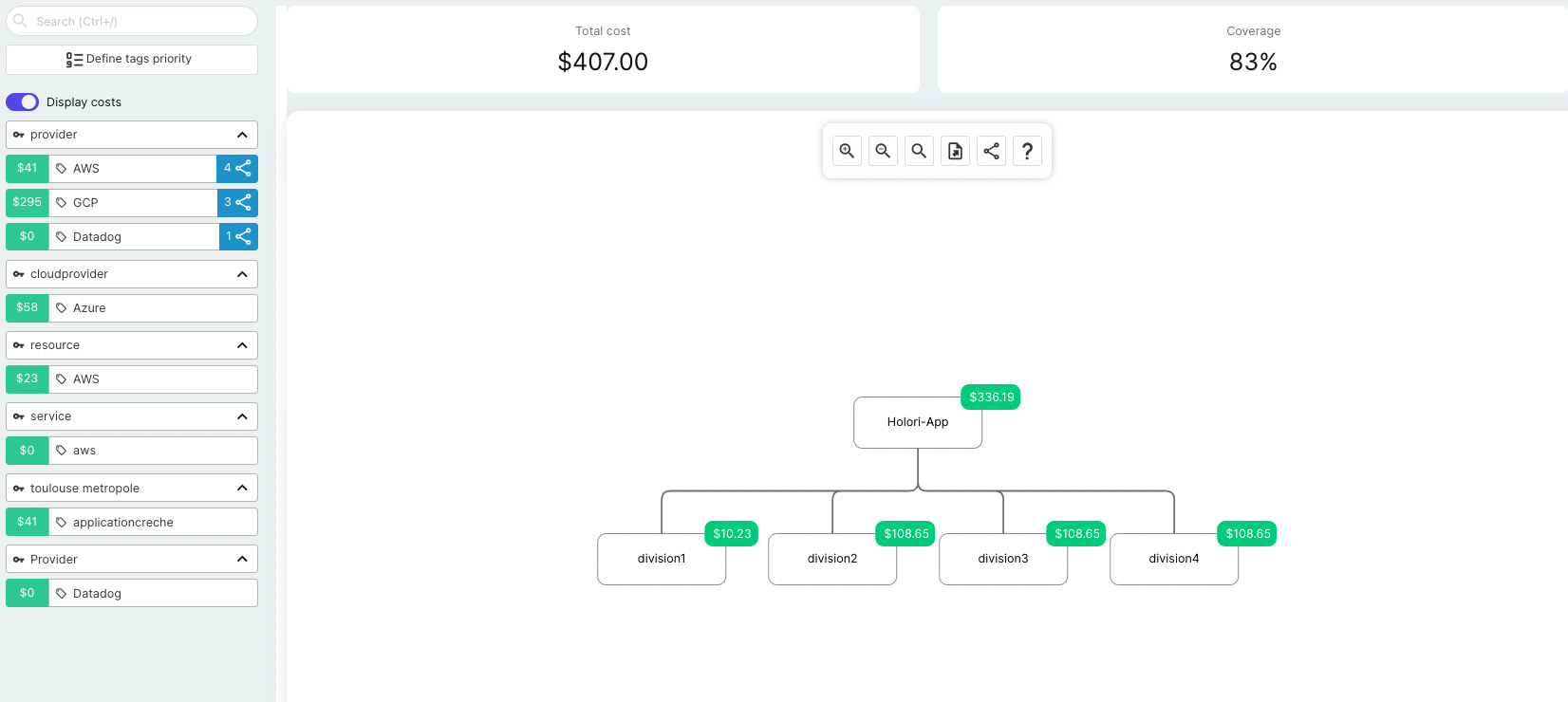
Virtual tags ensure that automated actions and alerts are routed to the correct owner even when infrastructure-level tagging is incomplete. Rather than an anomaly alert landing in an unowned inbox because the resource has no team tag, virtual tag rules apply the correct ownership mapping at the reporting layer, making every automated workflow traceable to a responsible team.
The daily infrastructure diff diagrams give platform and FinOps teams an immediate visual overview of what changed across the environment in the last 24 hours: new resources in green, deleted resources in red, modified resources in yellow. This change visibility is the foundation for anomaly investigation workflows, reducing the time between alert and root cause identification from hours to minutes.
FinOps automation is not a destination. It is a practice that compounds in value over time as the underlying data quality improves, the policy library grows, and the team’s confidence in automated actions increases. Start with alerting, build toward automated waste remediation, and expand to policy enforcement and anomaly response as the foundation matures. Each stage pays for the next.
Try Holori now and start automating FinOps tasks: https://app.holori.com/
Frequently Asked Questions
What is FinOps automation?
FinOps automation is the practice of embedding financial governance and cost optimization into cloud engineering workflows through automated policies, alerts, and actions. It covers a wide spectrum from basic budget alerting and tagging enforcement at provisioning time, to scheduled resource shutdowns, anomaly response workflows, AI-assisted commitment recommendations, and autonomous waste remediation agents. The goal is to move cost management from a periodic manual review process to a continuous automated practice that scales with the environment.
What are the prerequisites for FinOps automation?
Three things need to be in place before automating anything: billing data that is accurate and normalized across all cloud providers, cost allocation that attributes at least 80% of spend to a specific owner, and tagging coverage high enough to make automated actions traceable to a responsible team. Automating on top of unreliable data amplifies the problems rather than solving them. Anomaly alerts route to the wrong team, rightsizing actions fire on unowned resources, and policy violations appear in accounts where nobody knows who is responsible.
What should I automate first in a FinOps program?
Start with alerting and reporting automation: budget threshold notifications, anomaly alerts, and scheduled tagging compliance reports. These deliver immediate value with no risk of unintended impact on running workloads. Once alerting is reliable and tuned, move to automated identification of waste without automated remediation: continuous scanning for unattached volumes, idle instances, and orphaned snapshots that produces a prioritized action list for engineers to review. Automated remediation for low-risk, reversible actions comes next, followed by more advanced automation as confidence in the underlying data quality grows.
How does Terraform fit into FinOps automation?
Terraform is the most effective point of intervention for cost governance because it sits before resources are deployed rather than after. Integrating Infracost into Terraform pull requests surfaces the estimated monthly cost of every infrastructure change at code review time, before the resource exists. Open Policy Agent with Conftest or HashiCorp Sentinel can enforce cost governance rules directly in CI/CD pipelines, blocking or flagging configurations that violate defined policies (unapproved instance types, missing tags, storage without retention policies) before the plan is applied. This shift-left approach catches cost problems at the cheapest possible moment in the development cycle.
What is agentic FinOps?
Agentic FinOps refers to AI agents that autonomously identify and act on cloud cost optimization opportunities without waiting for human review and approval. Rather than generating a recommendation for an engineer to act on, an agentic system directly executes low-risk actions like deleting orphaned snapshots, terminating idle instances, or aborting incomplete multipart uploads. The most mature implementations use staged autonomy: agents operate in dry-run mode first to build a track record of accuracy, then execute reversible low-risk actions autonomously, while routing high-stakes decisions like commitment purchases or production rightsizing to a human approval workflow.
What should never be automated in FinOps?
Commitment purchasing (Reserved Instances, Savings Plans, Committed Use Discounts) should always require human approval before execution given the financial exposure of a one to three year term commitment. Production rightsizing should involve the team that owns the workload before any change is made, since an incorrect sizing change can cause latency spikes or service degradation that costs more to recover from than the optimization saves. Any irreversible action, deleting a resource with no backup, terminating a production instance, removing a snapshot that is the last recovery point, should require explicit human sign-off regardless of how mature the automation program is.