

The AI revolution is fundamentally transforming cloud & IT spending. According to Bloomberg Intelligence, the generative AI market is projected to explode from $40 billion in 2022 to $1.3 trillion by 2032, a staggering 42% annual growth. As organizations rapidly adopt multi-model, multi-provider AI strategies, a new financial reality has emerged: AI costs are no longer a minor line item but a substantial budget driver that demands rigorous FinOps discipline.
For FinOps practitioners accustomed to managing traditional cloud infrastructure costs, AI presents unique challenges that require specialized approaches to cost allocation, tracking, and optimization. This comprehensive guide explores the critical importance of AI cost allocation and how modern FinOps platforms like Holori are evolving to address these challenges.
Understanding FinOps Cost Allocation
Before diving into AI-specific challenges, it’s essential to understand the fundamentals of FinOps cost allocation. Cloud cost allocation is the practice of distributing cloud expenses among teams, projects, departments, or business units based on actual consumption. Rather than treating cloud and AI bills as monolithic expenses, effective allocation breaks costs down granularly, assigning ownership and responsibility to relevant stakeholders.
Traditional cloud cost allocation focuses on infrastructure resources like compute instances, storage volumes, databases, and network services. These resources are relatively straightforward to track once you’ve correctly tagged (or virtual-tagged them). However, AI workloads introduce entirely new dimensions of complexity that challenge conventional FinOps practices.
The Anatomy of AI Costs: Beyond Traditional Cloud Metrics
AI costs differ fundamentally from traditional infrastructure spending in several critical ways:
Token-Based Consumption Models
Unlike cloud services that bill by compute hours or storage capacity, AI models charge primarily based on token consumption. A token represents a chunk of text, typically a word fragment, complete word, or punctuation mark. Different AI providers use varying tokenization strategies, but the principle remains consistent: you pay for every piece of text processed. The concept remains the same for audio, image and video processing.
For context, consider these examples:
- The phrase “Hello, world!” contains approximately 4 tokens
- A typical business email (200 words) uses roughly 270 tokens
- A 10-page technical document contains approximately 3,500 tokens
- The complete works of Shakespeare contain roughly 1.2 million tokens
This token-based model creates non-linear, usage-dependent costs that fluctuate dramatically based on prompt length, response verbosity, and conversation complexity. A simple “hello” query costs fractions of a cent, while processing a comprehensive code review might cost several dollars—both appearing as single “API requests” in basic tracking.
Differentiated Input and Output Pricing
AI providers charge different rates for input tokens (the prompt you send) versus output tokens (the model’s response). This asymmetry reflects the computational reality that generating text requires significantly more processing than analyzing it.
Current pricing examples illustrate this disparity:
- Anthropic Claude Opus 4.1: $15 per million input tokens, $75 per million output tokens (5x differential)
- OpenAI GPT-4o: $5 per million input tokens, $15 per million output tokens (3x differential)
- Google Gemini Pro: $1.25 per million input tokens, $10 per million output tokens (8x differential)
Therefore, a chatbot that generates verbose responses will cost dramatically more than one that provides concise answers, even with identical input. Without proper allocation of input versus output consumption, teams cannot accurately understand their true cost drivers.
Model Tiering and Performance Trade-offs
AI providers offer multiple model tiers with vastly different price points and capabilities. The same query executed on different models can vary in cost by a factor of 100 or more:
- Premium Models (Claude Opus 4.1, GPT-4): $15-75 per million tokens, optimized for complex reasoning, coding, and high-stakes decisions
- Mid-Tier Models (Claude Sonnet 4.5, GPT-4o): $3-15 per million tokens, balanced performance for production workloads
- Economy Models (Claude Haiku, GPT-4o-mini): $0.25-4 per million tokens, optimized for high-volume, straightforward tasks
Organizations must allocate costs not just by consumption volume but by model selection decisions. A team defaulting to premium models for routine tasks can generate 50-100x higher costs than necessary.
The picture below shows some of the high-level billing variables for ChatGPT/OpenAI. As you can see, some of the elements mentioned above are listed there such as the input/output tokens, model, tiers, etc. These come particularly handy when you must perform your AI cost allocation.

Infrastructure Costs Beyond API Calls
For models you run directly on a cloud provider for example, you’ll still be charged for the per resource consumption. Advanced AI cost allocation must take this into account when digging into your cloud and AI costs.
Beyond API consumption, AI workloads incur substantial infrastructure expenses.
- GPU Compute: Self-hosted or fine-tuned models require expensive GPU instances, with costs ranging from $1-8 per hour for basic setups to $30-100+ per hour for enterprise-grade training infrastructure
- Model Training: Training custom models can cost thousands to millions of dollars depending on dataset size, model architecture, and iteration cycles
- Data Storage and Processing: Vector databases, embedding storage, and training datasets require specialized storage infrastructure
- Provisioned Throughput: For high-volume production workloads, providers offer dedicated capacity at fixed monthly rates, creating allocation challenges similar to reserved instances
Why AI Cost Allocation Is Critical in FinOps
The unique characteristics of AI costs create several critical challenges that make allocation essential:
Enabling Accurate Product Economics and ROI Analysis
- Cost per team or project: How much did each team or project spent on AI resources?
- Cost per User Interaction: How much does each chatbot conversation, document analysis, or code suggestion cost?
- Cost per Business Outcome: What’s the AI expense per customer support ticket resolved, sales lead qualified, or code commit generated?
These metrics are impossible to calculate without precise allocation of AI costs.
Supporting Chargeback and Showback Models
Many organizations operate under chargeback or showback models where departments are billed (or shown) their cloud or AI consumption:
Showback: Departments see their cloud and AI costs without direct billing, promoting awareness and transparency. This non-confrontational approach helps build cost consciousness without creating internal friction.
Chargeback: Departments are directly billed for their cloud and AI usage, enforcing strict financial discipline. This model ensures that teams with the authority to make spending decisions also bear the financial consequences.
Technical Challenges of AI Cost Allocation in FinOps
Implementing effective AI cost allocation faces several unique technical obstacles:
Inconsistent and Limited Native Tagging Support
Traditional cloud resources are often already tagged by the DevOps team, which eases cost allocation. However, this is sometimes imperfect and not always consistent from one provider to another.
AI API calls, by contrast, often provide limited or no native tagging capabilities. Many providers only track costs at the API key level, creating a “shared cost pool” problem. Organizations must implement custom tracking infrastructure to capture:
- Which application or team triggered the request
- Which exact product and service was used
- How much it cost in $ and tokens
Token Counting and Attribution Complexity
Accurate cost allocation requires precise tracking for every API interaction. However:
- Different models use different tokenization algorithms
- Some providers return token counts in API responses; others don’t
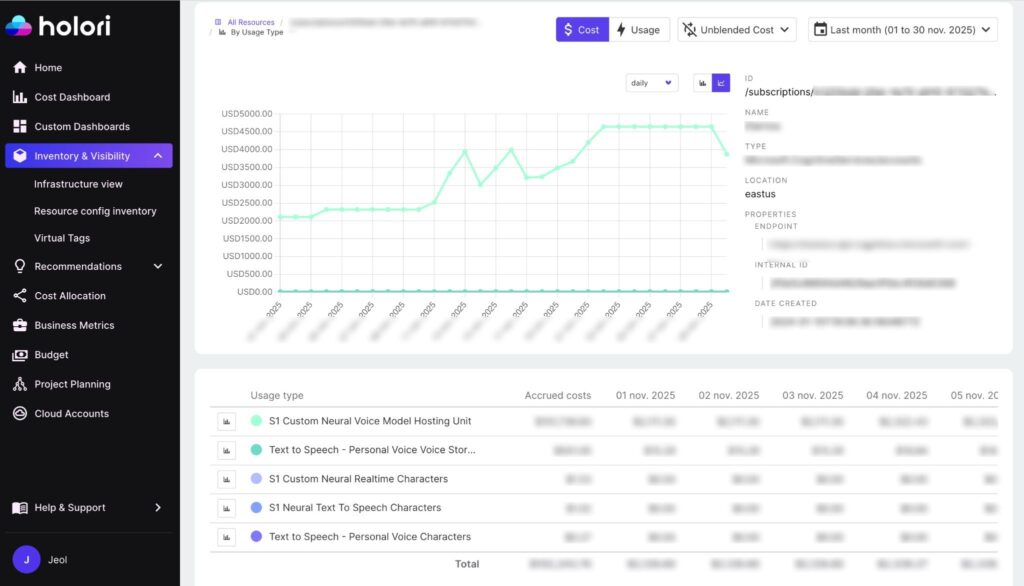
- Not all services are tracked at a token level (see below for the Azure text to speech example)
Decentralized AI Adoption
In many organizations, AI adoption happens organically across teams:
- Engineering teams integrate AI capabilities into applications
- Data science teams build custom models and pipelines
- Business units subscribe to AI-powered SaaS tools
- Individual contributors use AI coding assistants and productivity tools
This decentralized pattern creates visibility gaps. Without centralized governance and unified tracking, organizations discover AI costs scattered across:
- Direct API provider bills (OpenAI, Anthropic, Google)
- Cloud infrastructure bills (GPU instances, databases, VMs, etc.)
- SaaS application bills (AI-powered features in existing tools)
- Individual credit card statements (personal subscriptions)
How to Allocate AI Costs Using FinOps Best Practices
Effective AI cost allocation requires a multi-layered approach combining technical infrastructure, organizational policy, and continuous refinement:
1. Establish a Comprehensive Tagging Strategy
Just as with traditional cloud resources, AI costs require consistent tagging to enable meaningful allocation:
Request-Level Tagging: for each request: project id or application name, team or department, environement (dev/staging/prod), customer or user id, etc.
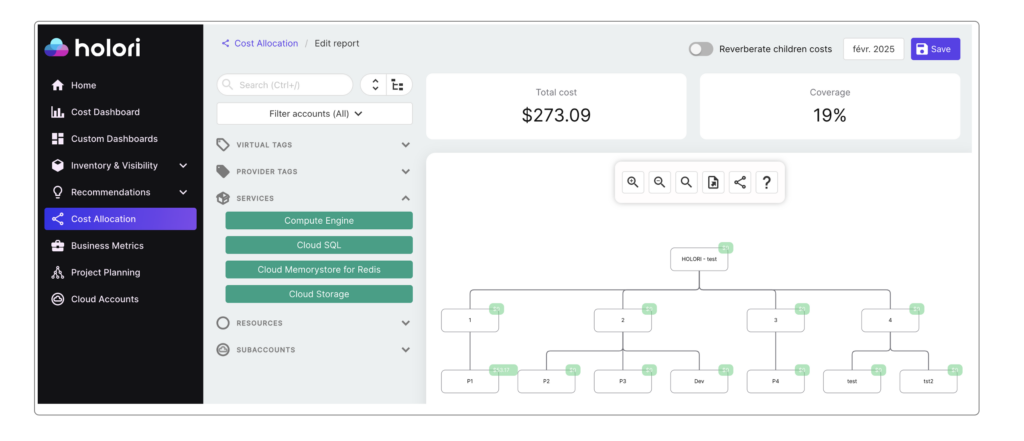
Virtual Tagging: For AI costs that can’t be tagged at the request level, leverage virtual tagging capabilities of FinOps solutions such as Holori, to apply allocation rules. The way the system is built allows any stakeholder to define tags without any access to each providers’ console. You can for example add your:
- Project names, cost centers, departments
- Environment designations (dev, staging, production)
- Owner information etc.
One of the advantages is to get an abstraction layer from the AI/cloud providers and ensure consistent tagging across absolutely all resources.
2. Implement Granular Usage Tracking
When applicable, capture AI consumption metrics at Token-Level Monitoring.
Track input and output tokens for every request, broken down by:
- Model type and tier
- Token input
- Token output
- Requests counts
For cloud providers’ native services:
Beside costs directly related to the storage and transfer of data, the billing of some AI products is similar to traditional cloud resources. Indeed, the cost per service can be detailed in multiple usage layers.
The illustration below shows the details for an Azure Text to Speech service tracked with Holori. By getting into the usage cost details, it becomes possible to allocate costs with an unprecedented granularity.
3. Define Shared Cost Allocation Rules
For costs that can’t be directly attributed to individual departments or teams, establish clear allocation methodologies. This can either be
- Proportional allocation: Distribute shared costs based on measurable usage. For example the data caching cost can be allocated per team in relation to the volume request of each team.
- Or a fixed percentage allocation. You have 4 teams and decide to allocate costs evenly between all of them.
4. Back to FinOps basics: Beyond simple AI Cost Allocation, implement Real-Time Visibility and Alerting
Cost allocation is usually made monthly at the beginning of each month once final invoices have been validated.
However, discovering overruns after the monthly bill arrives is insufficient for AI workloads with their non-linear cost dynamics:
Real-Time Cost Dashboards: Provide teams with live visibility into:
- Current spend trajectory and monthly forecast
- Cost per request, per user, per feature
- Defined Budgets and evolution tracking
- Anomalous usage patterns and cost spikes
Intelligent Alerting: Configure proactive alerts for:
- Cost thresholds exceeded (daily, weekly, monthly)
- Anomalous usage patterns (sudden spike in request volume or token consumption)
- Inefficient implementations (high retry rates, excessive prompt lengths, suboptimal model selection)
- Budget exhaustion predictions (projected to exceed limit within N days)
Usage Quotas and Guardrails: Implement protective limits:
- Token budgets per team, project, or feature
- Rate limiting for non-critical workloads during peak hours
- Automatic throttling when cost thresholds are exceeded
- Approval workflows for high-cost operations
Holori’s platform provides all these capabilities through its comprehensive alerting and budgeting features, adapted specifically for AI cost patterns.
Holori’s Approach to AI Cost Allocation
As AI becomes an increasingly dominant cost driver, Holori is evolving its platform to provide specialized capabilities for AI cost management:
Unified Multi-Provider Visibility
Holori aggregates AI costs across all major providers, OpenAI, Anthropic, Google, and others alongside traditional cloud infrastructure spending. This unified view enables:
- Total AI Spend Visibility: See all AI-related expenses in one place, regardless of provider
- Cross-Provider Comparisons: Compare costs across different AI providers
- Global Cost Attribution: Understand total technology spending per project, product, or team including both infrastructure and AI costs
Intelligent Virtual Tagging for AI Costs
Recognizing that many AI providers lack native tagging support, Holori’s virtual tagging system enables:
- Bulk Tagging and Standardization: Apply consistent tags across AI costs from multiple providers using rules and automation
- Hierarchical Cost Structures: Design organizational cost hierarchies by business unit, department, project, or custom dimensions
- Drag-and-Drop AI Cost Allocation: Visually organize AI costs using Holori’s intuitive hierarchical diagrams
- Retroactive Tag Application: Apply allocation rules to historical costs to enable trend analysis and reporting
Advanced AI Cost Allocation Features
Holori’s platform includes specialized capabilities for AI workload challenges:
- Token-Level Cost Tracking: Capture and report costs at the individual token level for maximum granularity
- Model-Specific Attribution: Track spending by AI model tier to identify opportunities for workload shifting
- Anomaly Detection: Machine learning-powered identification of unusual AI spending patterns
Integration with Existing FinOps Workflows
AI cost allocation integrates seamlessly with Holori’s established FinOps capabilities:
- Unified Cost Dashboards: AI costs appear alongside cloud infrastructure in comprehensive financial views
- Budget Management: Set and track budgets that include both traditional and AI spending
- Alerting and Governance: Unified alerting rules that span infrastructure and AI costs
- Chargeback and Showback: Generate allocation reports that include complete technology spending
Conclusion: AI Cost Allocation as Competitive Advantage
AI is transforming industries by enabling new capabilities and business models. However, without rigorous cost management, AI spending can quickly spiral into a budget crisis that undermines the technology’s value proposition.
Holori’s platform provides the comprehensive FinOps capabilities required to thrive in this AI-driven future. By combining unified multi-cloud visibility with specialized AI cost tracking, intelligent virtual tagging, and powerful allocation tools, Holori enables organizations to harness AI’s transformative potential while maintaining complete financial control.
Ready to take control of your AI costs? Explore Holori’s AI cost allocation capabilities at https://app.holori.com/



