Cloud waste is no longer a marginal inefficiency. In 2026, it is one of the primary drivers of uncontrolled cloud spend, especially in organizations operating across multi-cloud and Kubernetes environments. Despite years of FinOps maturity, most companies still underestimate how much of their infrastructure is either idle, underutilized, or simply forgotten.
This guide goes beyond surface-level recommendations. It provides a structured, expert-level approach to identifying unused resources, understanding why they persist, and implementing scalable detection mechanisms. It also explains how modern FinOps platforms like Holori enable continuous waste identification across complex architectures.
What Is Cloud Waste in 2026?
Cloud waste refers to any cloud resource that generates cost without delivering proportional business value. While this definition seems straightforward, the reality is nuanced.
In 2026, waste is no longer limited to obvious cases like unattached storage volumes or stopped instances. It increasingly stems from:
- Ephemeral infrastructure that outlives its purpose
- Over-provisioned Kubernetes workloads
- Forgotten test environments
- Misaligned autoscaling configurations
- Idle managed services that remain “available” but unused
The shift to platform engineering and self-service infrastructure has amplified the problem. Teams can spin up resources instantly, but governance mechanisms often lag behind.
Why Unused Resources Persist
Despite being a key priority (see below the graph from the FinOps foundation), eliminating cloud waste is still not done efficiently.
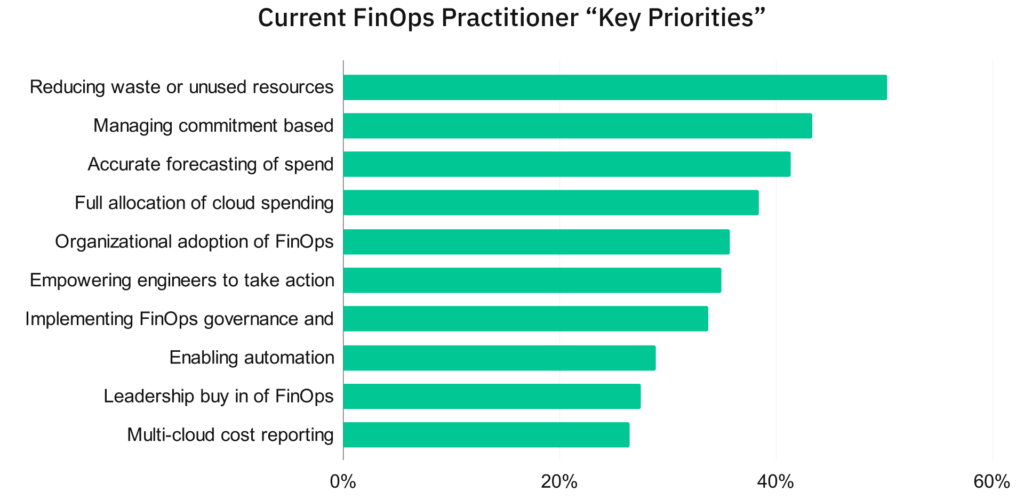
Source FinOps Foundation
But, understanding why waste exists is more important than simply detecting it.
First, organizational fragmentation plays a major role. Engineering teams optimize for speed and reliability, not cost. Once a resource is deployed, ownership can rapidly become unclear, especially in large environments.
Second, cloud providers have optimized for availability over efficiency. Default configurations tend to over-provision. For example, managed databases, load balancers, and Kubernetes clusters are rarely right-sized out of the box.
Third, visibility remains a challenge. Even with cost dashboards, mapping resources to actual usage or business value is complex. Tags are often incomplete or inconsistent, and cost allocation models do not always reflect real consumption.
Finally, the rise of automation introduces a paradox: infrastructure is easier to create than to clean up. CI/CD pipelines and infrastructure-as-code accelerate provisioning but rarely include robust decommissioning logic.
The Main Categories of Unused Cloud Resources
To effectively identify waste, you need a taxonomy. Not all unused resources are equal, and detection methods differ depending on the category.
Idle Compute Resources
These are virtual machines or instances that are running but show little to no CPU, memory, or network activity over extended periods.
In practice, many workloads exhibit bursty behavior, which makes simple threshold-based detection unreliable. Advanced approaches rely on time-series analysis to distinguish between legitimate low usage and true idleness.
Tagging also plays a role as quickly identifying the resource owner or project makes it easy to get in touch with the right person and ask about its usefulness.
Orphaned Storage
Storage volumes, snapshots, and object storage buckets frequently become detached from active workloads.
Snapshots are particularly problematic. Automated backup policies generate them continuously, but retention policies are often poorly defined. Over time, they accumulate silently and represent a significant portion of waste.
Zombie Kubernetes Resources
Kubernetes introduces a new layer of complexity. Resources such as pods, persistent volumes, and load balancers may persist even after the application lifecycle has ended.
Common examples include:
- PersistentVolumeClaims that remain after a namespace is deleted
- Load balancers created by services that are no longer active
- Over-requested CPU and memory that are never actually consumed
Unlike traditional infrastructure, Kubernetes waste is harder to detect because costs are abstracted at the cluster level.
Unused Managed Services
Managed databases, message queues, and analytics services can remain active with minimal or zero usage.
These services often have a baseline cost simply for being provisioned. Since they are “healthy” from a system perspective, they rarely trigger alerts.
Forgotten Development Environments
Temporary environments created for testing, staging, or demos are a major source of waste.
They are typically spun up quickly and rarely tracked systematically. Without automated lifecycle policies, they can persist indefinitely.
Detection Strategies: From Basic to Advanced
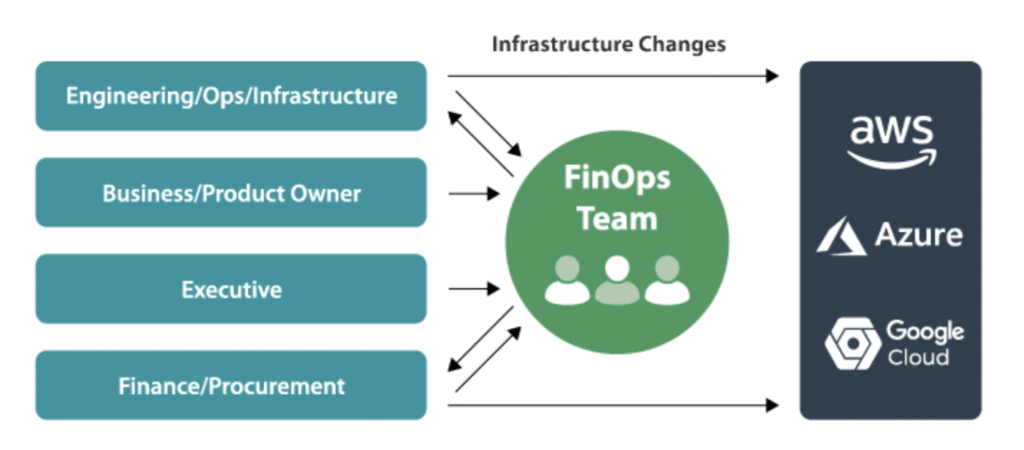
Source FinOps Foundation
The FinOps team is at the core of the cloud cost optimization strategy.
Identifying unused resources requires more than periodic audits. It demands continuous, automated analysis. It also requires continuous coordination with all department from business to engineering.
Metrics-Based Detection
The most common approach is to analyze utilization metrics such as CPU, memory, disk I/O, and network activity.
While useful, this method has limitations. Low utilization does not always mean a resource is unnecessary. Some workloads are intentionally idle but critical.
Time-Based Heuristics
Resources that have not shown activity over a defined period (for example, 30 or 60 days) can be flagged as candidates for cleanup.
This approach is simple but effective for storage and development environments. However, it must be adapted to each resource type.
Dependency Mapping
A more advanced technique involves mapping dependencies between resources.
For example, identifying whether a storage volume is attached to an active instance, or whether a load balancer is routing traffic. This requires a graph-based view of the infrastructure (see below for a real life example).
Cost-to-Usage Correlation
One of the most powerful methods is correlating cost data with actual usage.
If a resource generates significant cost but negligible usage, it becomes a high-priority candidate for optimization. This approach aligns directly with FinOps principles.
The Limits of Native Cloud Tools
Cloud providers offer native tools for cost optimization, but they are often insufficient in complex environments.
They typically:
- Focus on single-cloud visibility
- Provide recommendations without context
- Lack advanced allocation models
- Do not integrate deeply with Kubernetes or multi-cloud setups
Moreover, native cloud optimization tools have some limitations. For example, on AWS, daily data granularity is limited to 14 days only and you get poor access to details resource cost usage. This is particularly problematic if you need to compare the activity of a ressource between two different months.
The alerting system natively available is also limited to non-existent depending on the platform. Loosing direct feedback from your infra in case of unexpected inactivity is a massive blindspot. This is also true in the opposite direction for unexpected cost spikes. Hunting cloud waste to optimize your cloud costs is also a great opportunity to spot other inefficiencies.
As a result, organizations relying solely on native tools often miss a significant portion of their waste.
Building a Continuous Waste Detection Framework
To move beyond reactive cleanup, organizations need a structured framework.
As you can see on this FinOps Optimization Process Flow from the FinOps Foundation, several stakeholders, policies and output are interrelated.
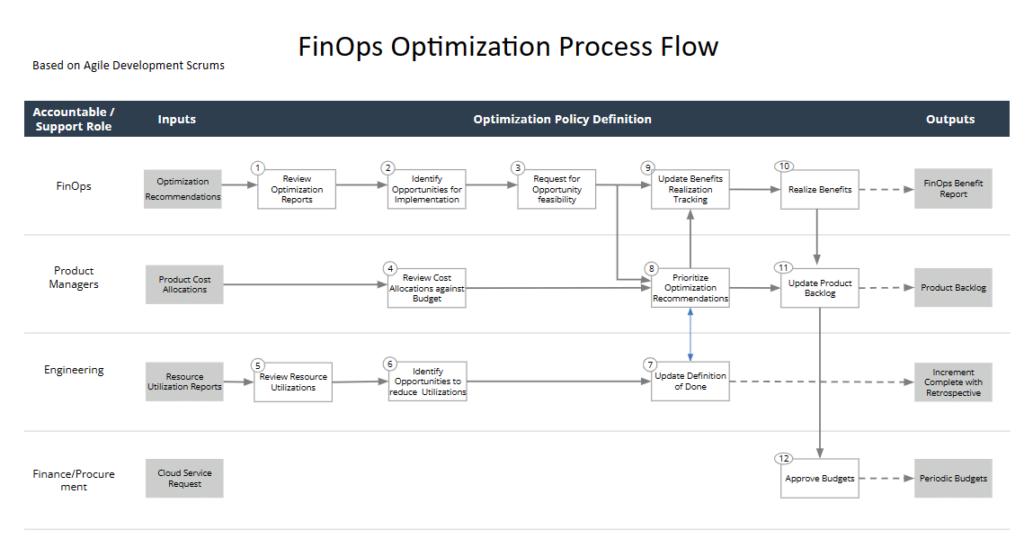
Source FinOps Foundation
The most effective setups share a few characteristics, they:
- Centralize cost and usage data across all cloud providers and Kubernetes clusters. This unified view is essential for identifying cross-environment inefficiencies.
- Implement consistent tagging and ownership models, ensuring that every resource can be traced back to a team or project.
- Automate detection using customizable rules, rather than relying on static thresholds.
- Integrate waste detection into engineering workflows, making cost optimization part of the development lifecycle rather than an afterthought.
Why Holori Changes the Game
Holori is designed specifically to address the limitations of traditional cost management tools.
Unlike generic dashboards, it provides a modeling layer that maps infrastructure to real-world architecture. This is critical for identifying unused resources in context, not in isolation.
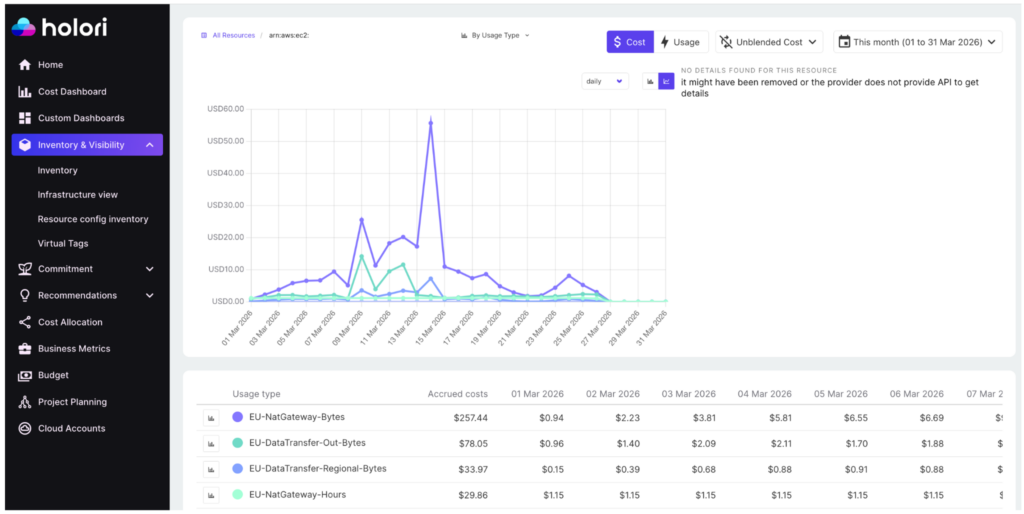
By giving access to multi-year data history with daily granularity (see above), teams can explore each resource’s usage and evolution. It makes it much easier to stop services that have no activity.
Holori also enables the precise allocation of any usage cost to the right team or project. With its advanced notification system, configure alerts to make sure a resource does not go below a certain threshold. And don’t worry, the opposite is also possible, be alerted when the costs start to skyrocket!
Holori enables:
- A precise understanding of how resources are connected, making it easier to detect orphaned components.
- Advanced cost allocation across multi-cloud and Kubernetes environments, ensuring that waste is visible at the right level of granularity.
- A visual approach to infrastructure analysis, helping teams quickly identify anomalies that would be difficult to detect in raw data.
The screenshot below shows an example of an EBS volume unattached to a VM. Being able to visualize it on a graph makes it much easier than digging through an endless list on the provider’s console.
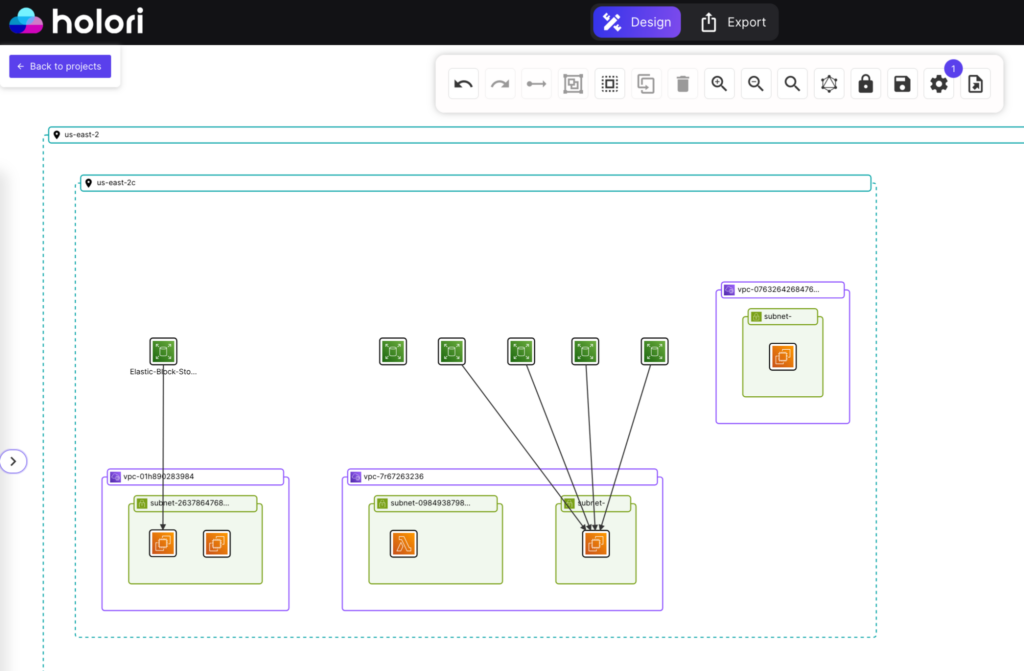
Most importantly, Holori aligns technical and financial perspectives. It bridges the gap between engineering teams and FinOps practitioners, enabling faster and more confident decisions.
From Identification to Action
Detecting unused resources is only the first step. The real challenge lies in acting on these insights.
In mature organizations, cleanup processes are automated wherever possible. Idle resources are either shut down or flagged for review. Development environments are tied to expiration policies. Storage lifecycle rules are enforced systematically.
At the same time, governance is balanced with flexibility. The goal is not to restrict innovation, but to ensure that efficiency scales with it.
The Future of Cloud Waste Management
As cloud environments continue to evolve, waste will become more subtle and harder to detect.
The rise of AI workloads, serverless architectures, and platform engineering will introduce new forms of inefficiency. Traditional metrics will no longer be sufficient.
Future-proof organizations will rely on:
- Deeper integration between cost data and observability
- Real-time anomaly detection powered by machine learning
- Infrastructure modeling to understand system-level impact
- Tighter feedback loops between engineering and finance
Holori is already positioned in this direction, providing the foundation for a new generation of FinOps practices.
Ready to give it a try? Go now to https://app.holori.com
FAQ
What is the biggest source of cloud waste today?
In most organizations, the largest contributors are idle compute resources, over-provisioned Kubernetes workloads, and forgotten development environments. However, the exact distribution depends heavily on the maturity of FinOps practices.
How can I quickly identify unused resources?
Start with utilization metrics and time-based heuristics, but combine them with dependency analysis for better accuracy. A unified platform like Holori significantly accelerates this process by correlating cost, usage, and architecture.
Are cloud provider recommendations enough?
No. Native tools provide useful insights but lack the depth and context required for complex, multi-cloud environments. They should be complemented with specialized FinOps solutions.
How often should I audit cloud waste?
Manual audits should be replaced with continuous monitoring. Waste detection needs to be automated and integrated into daily operations to be effective.
Can Kubernetes waste really be significant?
Yes. Kubernetes often hides inefficiencies due to its abstraction layer. Over-requested resources, unused volumes, and idle services can represent a substantial portion of total cloud spend.
How does Holori help reduce cloud waste?
Holori provides a comprehensive view of your infrastructure, combining cost data with architectural context. This enables precise identification of unused resources and supports informed decision-making through simulation and modeling.
Is cloud waste elimination realistic?
Complete elimination is unrealistic, but significant reduction is achievable. The goal is to continuously minimize waste while maintaining performance and reliability.