Cloud spending is not like a utility bill. You cannot look at it once a month, wince, and move on. It changes constantly, driven by deployments, team growth, new services, and a pricing model that nobody fully memorizes. That is exactly why the FinOps community built a structured approach to managing it, and why understanding the three core FinOps phases is the starting point for anyone serious about cloud financial management.
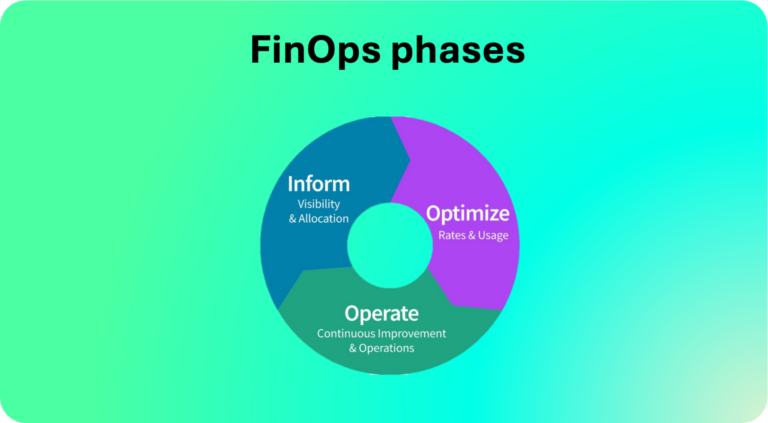
The FinOps lifecycle is built around three phases: Inform, Optimize, and Operate. At first glance they look simple, almost too simple. But the teams that get real results from FinOps are the ones who understand what these phases actually demand in practice, and more importantly, why cycling through them continuously is the whole point.
This article walks through each phase in depth, explains how they interact with each other, and sets the stage for a harder conversation: why the majority of organizations get stuck partway through, and what it takes to break out.
The Lifecycle Is a Loop, Not a Checklist
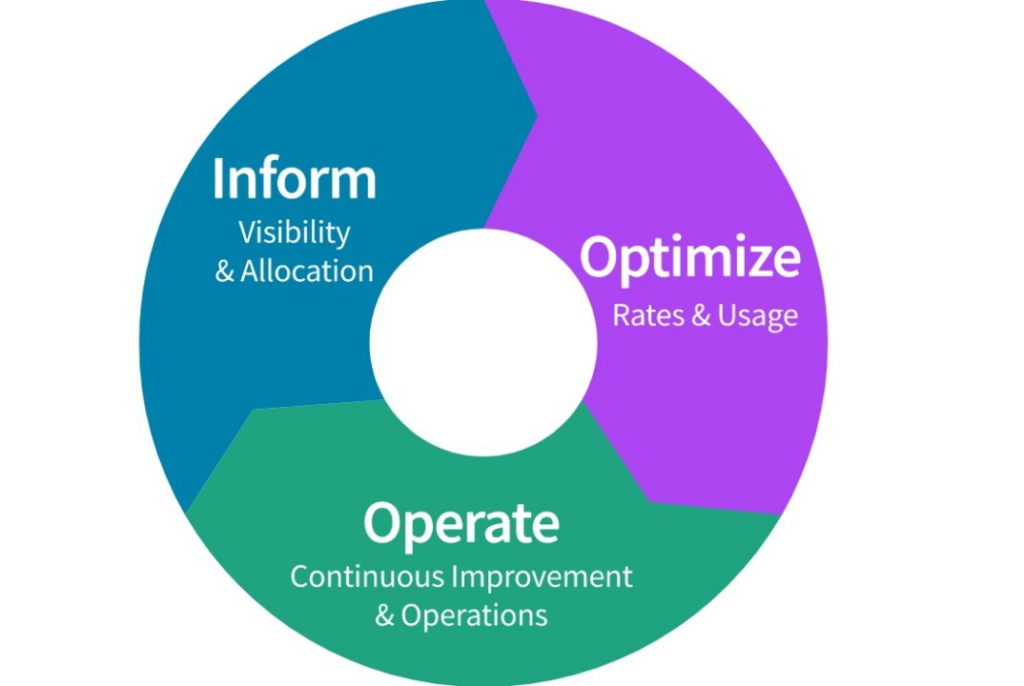
The first thing to understand about the FinOps phases is that they are not sequential steps you complete once and move on from. They form a continuous loop. Your team examines the current state of cloud usage in the Inform phase, identifies improvements in Optimize, acts on them in Operate, then circles back to Inform to see what changed. Then you do it again.
This matters because cloud environments are not static. A rightsizing decision you made in Q2 may be irrelevant by Q4 if your engineering team deployed three new services. A commitment you purchased last year might be covering workloads that no longer exist at the same scale. Optimization is not a project with an end date. It is an operational discipline.
The FinOps Foundation describes it well: different members of a FinOps team can work in different phases simultaneously, at different cadences, across different parts of the infrastructure. One team might still be in Inform mode for their Kubernetes costs while another is deep in Operate for their compute commitments. That is not a problem. That is normal.
Phase 1: Inform
What it actually means to have visibility
Inform is the foundation. Without it, the other two phases are guesswork. The goal here is straightforward: know where your money is going, who is spending it, and whether what you are seeing reflects reality.
In practice, this phase covers a few distinct activities. Cost allocation is the first and often the most painful. It means tagging cloud resources accurately so spend can be attributed to teams, products, environments, or cost centers. Most organizations underestimate how hard this is. Tags get missed, naming conventions drift, and untagged resources pile up. Getting allocation right is a prerequisite for everything else.

Benchmarking is the next layer. Once you can see costs broken down by team or service, you need a reference point. What is good performance? What is a warning sign? Internal benchmarks compare teams or time periods against each other. External benchmarks compare your unit economics against industry peers.
Forecasting rounds out the phase. Finance teams need to plan. They need to know whether cloud spend will grow 15% or 40% next quarter. Without accurate forecasting, every budget conversation is adversarial because nobody trusts the numbers. The Inform phase is what gives those numbers credibility.
One thing that surprises people about Inform is that it never really ends. Because cloud usage changes constantly, the data you built visibility around last quarter may not tell the full story today. Returning to Inform is not a sign that you failed at Optimize or Operate. It is the whole mechanism working as intended.
Phase 2: Optimize
Finding the right levers and actually pulling them
Once you have clear visibility from the Inform phase, Optimize is where you identify what to do about it. This phase has two distinct dimensions that are often conflated: usage optimization and rate optimization.
Usage optimization means consuming fewer resources to get the same outcome. Rightsizing is the most common example. An instance provisioned at peak capacity to handle a product launch six months ago may be running at 8% utilization today. That is waste. Eliminating idle resources, adjusting autoscaling policies, modernizing architectures to take advantage of serverless or containers, these all fall under usage optimization.
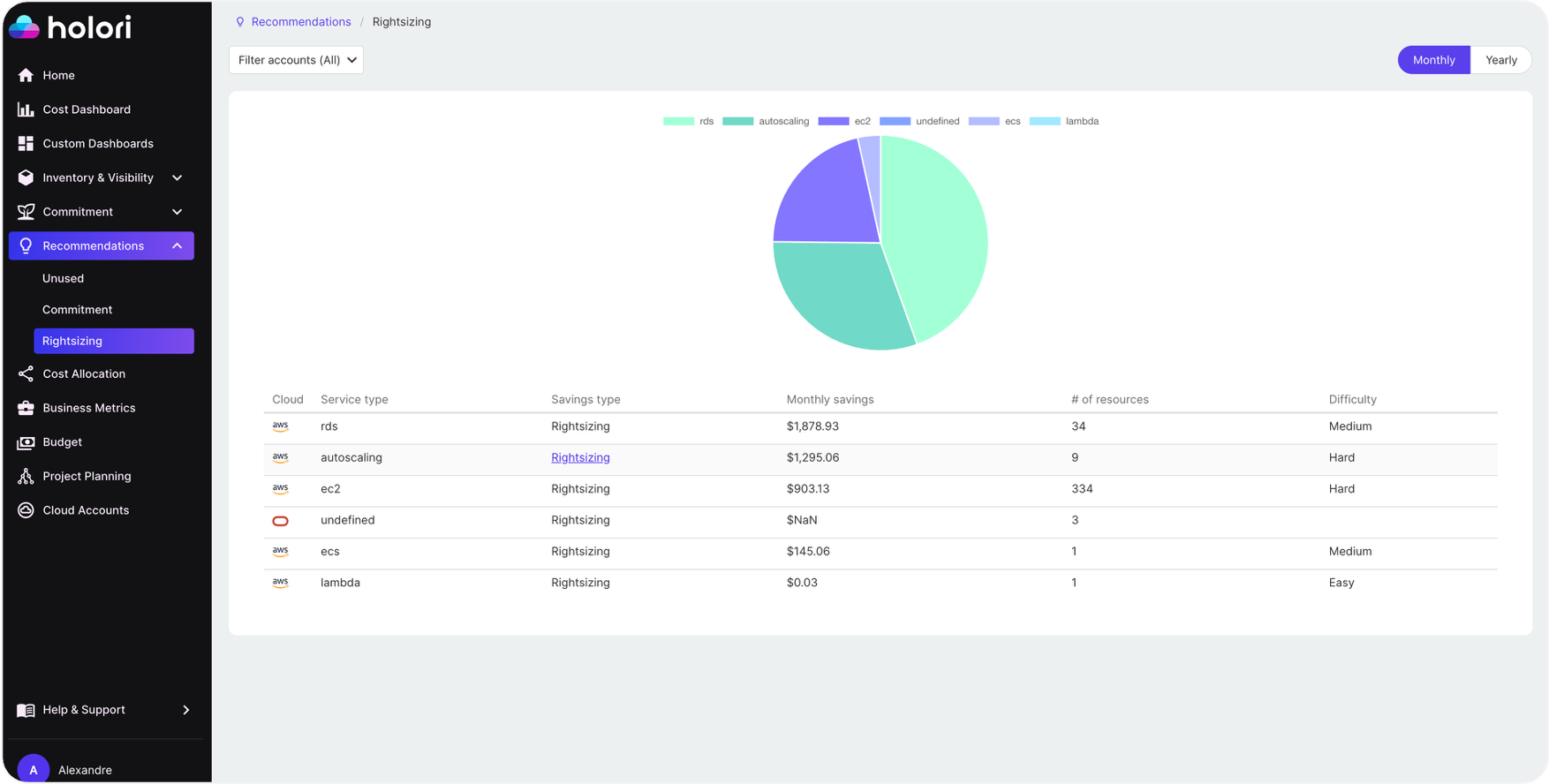
Rate optimization is different. It means paying less for the resources you are going to use anyway. Committed use discounts, reserved instances, savings plans, spot instances for fault-tolerant workloads. The insight from Inform tells you what your baseline usage looks like, and rate optimization turns that baseline into a purchasing strategy.
The reason teams trip up in this phase is usually not a lack of ideas. It is a lack of prioritization. A serious multi-cloud environment will surface dozens of optimization opportunities at once. Not all of them are worth acting on. Some require engineering effort that costs more than the potential saving. Others carry risk if workloads are not well understood. The skill in Optimize is knowing which opportunities represent the best return on effort, then building a process to act on them consistently.
Multi-cloud environments add another layer of complexity here. Optimization logic for AWS Reserved Instances does not translate directly to Azure Reserved VM Instances or GCP Committed Use Discounts. Each provider has its own commitment mechanics, discount thresholds, and flexibility rules. Teams operating across AWS, Azure, and GCP need to optimize within each provider’s pricing model while maintaining a unified view of overall efficiency.
Phase 3: Operate
Embedding FinOps into how your organization actually works
Operate is where the hard work of the first two phases either compounds into lasting results or evaporates. This phase is about embedding cost governance into daily operations so that FinOps is not a periodic review exercise but an ongoing organizational behavior.
What does that look like in practice? It starts with accountability. Engineering teams need to own their cloud spend the way they own their service reliability. That means having access to cost data in the tools they already use, getting anomaly alerts before spend spikes become invoice surprises, and having cost impact be part of how architectural decisions get evaluated before deployment, not after.
Finance teams need reliable forecasting data they can trust. They should not be pulling numbers from a spreadsheet that someone last updated three weeks ago. Real-time or near-real-time cost data connected to budget frameworks changes how finance participates in cloud decisions, from reactive budget reviewer to proactive partner.

Governance is the third pillar of Operate. Policies that define what is allowed, what triggers a review, and what requires approval before provisioning. Not bureaucratic controls for their own sake, but guardrails that prevent the kind of unchecked spend that creates end-of-quarter surprises. Automation is increasingly doing this work: budget thresholds that trigger Slack alerts, policies that flag resources without required tags, workflows that escalate anomalies to the right person without requiring anyone to go looking.
The most mature organizations treat Operate as the phase where FinOps becomes invisible in the best possible sense. Cost awareness is built into the engineering culture. It shows up in pull request reviews, architecture discussions, and quarterly planning. Nobody has to remind anyone to think about cloud costs because it is already part of how decisions get made.
How the Three FinOps Phases Interact
The phases are interdependent in ways that become obvious once you work through the loop a few times. Inform feeds Optimize by surfacing what to act on. Optimize feeds Operate by determining what changes to implement and govern. Operate feeds back into Inform by changing the environment and requiring a fresh look at the data.
A concrete example makes this clear. Your Inform phase reveals that one product team’s compute spend jumped 60% over 30 days. Optimize identifies two drivers: a fleet of oversized instances and a batch processing job that now runs continuously when it should run on a schedule. Operate implements the changes: the instances get rightsized through an infrastructure-as-code update, the batch job gets a cron trigger and an autoscaling policy. Next Inform cycle, you validate the impact and check whether the changes held.
That loop, running continuously across different parts of the infrastructure at different cadences, is what FinOps looks like when it is working. It is not glamorous. It is operational. But over time, the compounding effect of those small cycles is enormous.
What Running the Loop Actually Buys You
The practical value of cycling through the FinOps phases consistently goes beyond the obvious. Yes, you spend less. But the more durable benefit is that spending decisions stop being political and start being factual. When cost data is visible, consistently attributed, and updated in near real time, arguments about whether a service is over-provisioned or a team is overspending become much shorter. The answer is in the data.
This matters most at the organizational level. One of the deeper problems in cloud cost management is that engineering, finance, and operations tend to operate from completely different pictures of what is happening. Engineering sees utilization and performance. Finance sees invoices and variances. Operations sees uptime and incidents. None of those views alone is enough to make good decisions, and when they contradict each other, nothing moves. The FinOps lifecycle, when it is working, builds a shared view that all three groups can reason from. That shared view is what turns cloud cost management from a finance audit into an operational discipline everyone participates in.
The other thing the loop buys you is compounding returns. Individual optimizations are finite. A rightsizing exercise or a commitment purchase captures value once. But a team that runs the Inform, Optimize, Operate cycle consistently across quarters builds institutional knowledge: which workloads are predictable enough for commitments, which teams respond to visibility and which need harder guardrails, where structural waste tends to reappear. That knowledge does not depreciate. It makes every future cycle faster and more effective than the last.
FinOps Maturity and the Crawl, Walk, Run Model
The FinOps Foundation also describes a maturity model called Crawl, Walk, Run. It is important to understand that this is a separate concept from the three FinOps phases. Inform, Optimize, and Operate describe what you do. Crawl, Walk, Run describes how well you do it.
Every organization runs through all three phases, regardless of maturity. The difference is in the quality, consistency, and depth of execution. A team at Crawl is doing Inform, Optimize, and Operate too. They just do it inconsistently, manually, and with limited organizational buy-in. A team at Run does the same three things, but with automation, strong cross-functional alignment, and processes that have been refined over multiple cycles.
Crawl looks like this: billing exports are set up, there is some rough cost visibility by account or service, and someone reviews the bill at the end of the month. Optimization happens reactively, usually after a budget conversation goes badly. Governance barely exists. It is a starting point, not a destination.
Walk means the fundamentals are solid. Tagging coverage is high, cost is allocated by team and product on a consistent basis, optimization reviews happen on a regular cadence, and governance policies are documented and followed. Most organizations that have invested meaningfully in FinOps land here. According to the FinOps Foundation’s State of FinOps report, Walk is where the majority of practitioners sit.
Run means the loop is automated and deeply embedded in how the organization operates. Anomaly detection fires before engineers notice a problem. Commitment purchases are managed with data-driven models. Cost impact is evaluated before infrastructure changes go to production. Engineering, finance, and business teams share the same metrics and move together.
The reason the distinction matters: organizations sometimes diagnose the wrong problem. They think they need a better Optimize strategy when the real issue is that their Inform phase is still at Crawl, producing data nobody trusts. Or they invest in governance tooling for Operate while their tagging coverage is too low to make any of it meaningful. Maturity has to progress across all three phases together. A Run-level Optimize capability built on a Crawl-level Inform foundation will underperform every time.
The gap between Walk and Run is where most organizations stall. They have the tooling, the processes, and the dedicated practitioners. But the results are not compounding the way they expected. Understanding why that happens, and what it actually takes to break through, deserves its own dedicated discussion.
Where Holori Fits In

The FinOps lifecycle only works if the data underneath it is trustworthy. That is harder than it sounds in a multi-cloud environment. AWS, Azure, and GCP each produce billing data in their own format, at their own granularity, with their own tagging logic. Before your Inform phase can tell you anything useful, someone has to normalize all of that into a single coherent picture. Done manually, it is slow and brittle. Done wrong, every downstream decision in Optimize and Operate is built on numbers nobody fully trusts.
Holori connects to all three major hyperscalers and handles that normalization layer, so FinOps teams can spend their time on analysis rather than data wrangling. Cost allocation, anomaly detection, and cross-cloud benchmarking all depend on having clean, consistent data as input. That is what the platform provides.
Where it becomes particularly relevant right now is AI spend. As engineering teams adopt managed AI services across Bedrock, Vertex AI, and Azure OpenAI, that spend lands in the same billing streams as the rest of infrastructure but with almost no allocation logic out of the box. Holori captures those costs and makes them visible at the model and workload level, so AI spending enters the Inform phase like any other cloud cost rather than sitting in a blind spot until someone notices the invoice.
For teams pushing from Walk toward Run, the limiting factor is rarely ideas. It is having data that is granular enough, current enough, and consistent enough to support automation and governance at scale. That is the foundation Holori is built to provide.
What Comes Next after the Finops Lifecycle?
Understanding the three FinOps phases is the right starting point. But knowing the framework and executing it well are two different things. The State of FinOps data is clear: only a small fraction of organizations reach Run maturity, even among those who have been practicing FinOps for years.
The reasons for that stall are specific and addressable. Organizational silos between engineering and finance, tooling that surfaces data without driving action, optimization programs that focus on rate discounts while leaving structural waste untouched. These are not philosophical problems. They are operational ones.
FAQ
What are the three FinOps phases?
The three FinOps phases are Inform, Optimize, and Operate. Inform is about gaining visibility into where cloud spend is going and who is responsible for it. Optimize is about identifying and acting on opportunities to reduce waste or improve rates. Operate is about embedding cost governance into daily workflows so improvements hold over time. The phases form a continuous loop rather than a one-time sequence.
What is the difference between the FinOps phases and the Crawl, Walk, Run maturity model?
They answer different questions. The three phases describe what FinOps teams do: gather visibility, find improvements, govern consistently. Crawl, Walk, Run describes how well they do it. Every organization works through all three phases regardless of maturity level. The maturity model reflects the quality and consistency of execution across those phases, not which phase a team is currently in.
Do you need to complete one phase before starting the next?
No. The phases are not sequential gates. Different teams within the same organization can be in different phases simultaneously, and for different parts of their infrastructure. A team might be deep in Optimize for compute spend while still building out Inform for their Kubernetes costs. That is normal and expected.
How long does it take to see results from FinOps?
Early wins from the Optimize phase, particularly rightsizing and eliminating idle resources, can show up within the first cycle. The more durable gains come from running the loop consistently over several quarters, as teams build institutional knowledge about their cloud environment and shift from reactive cost management to proactive governance.
Where do most organizations struggle with the FinOps lifecycle?
The most common sticking point is the gap between Walk and Run maturity. Teams have the processes in place but struggle to automate them, get consistent cross-functional buy-in, or move fast enough to keep pace with a changing cloud environment. That is the focus of the next article in this series.