AI spend is no longer a footnote in the cloud bill. For most engineering organizations, it is becoming one of the fastest-growing line items they have, and one of the hardest to understand. A single Azure OpenAI entry in your invoice tells you almost nothing useful. Which team drove it? Which model? Which feature? Was it expected?
Traditional cloud cost management tools were not built to answer those questions. They were built for compute, storage, and networking: resources you provision, rightsize, and reserve. AI API costs work differently. They scale with usage at the request level, they vary by model, and the optimization levers sit inside application code, not inside a cloud console.
The tools below represent the current landscape for AI cost visibility. Some are purpose-built for AI workloads. Others are established FinOps or observability platforms extending their capabilities in that direction. All of them are worth understanding if you are trying to get serious about managing AI spend.
Discover now the Top Top 10 AI Cost Visibility Tools in 2026.
1. Holori

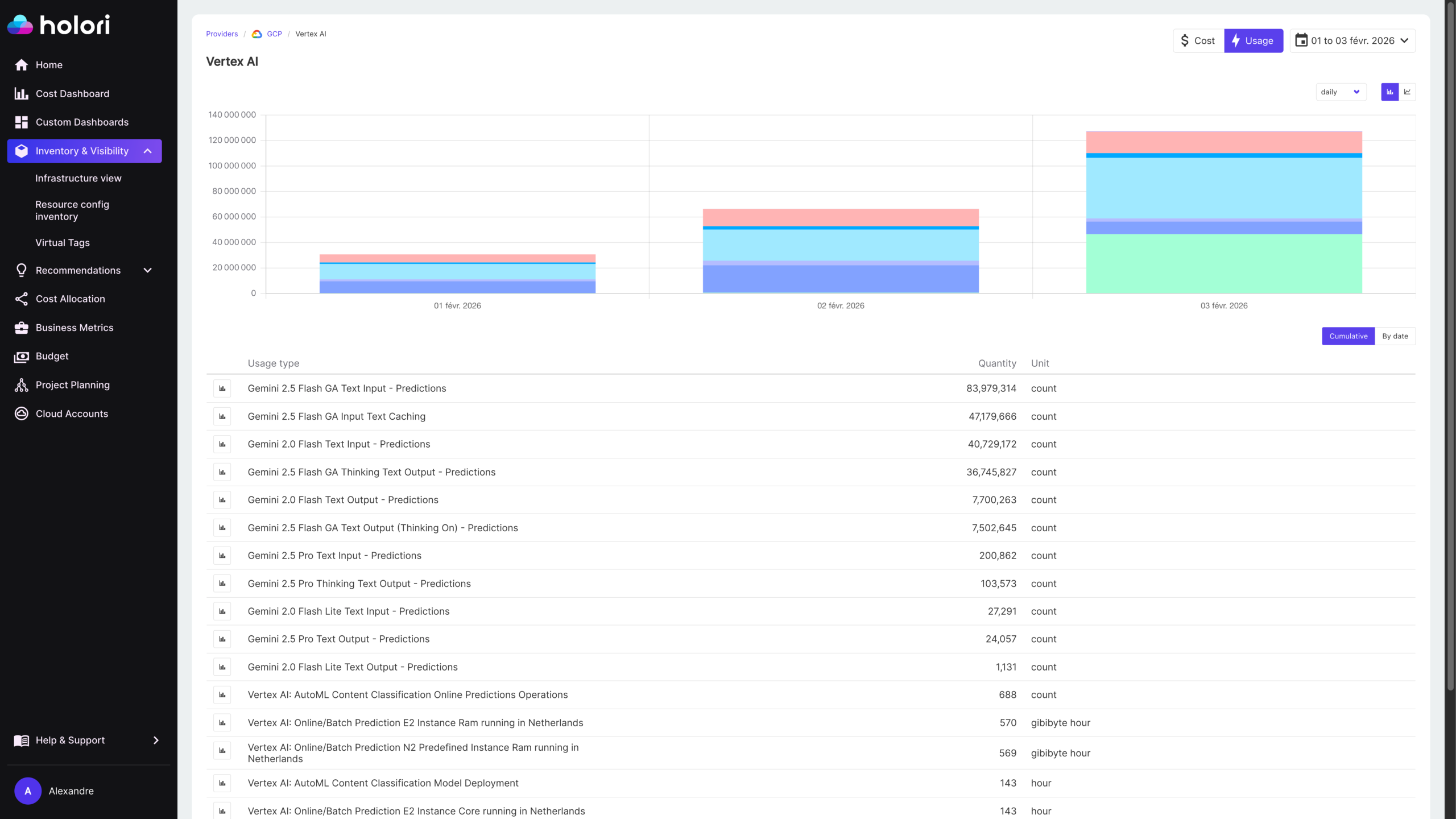
Holori is a multi-cloud FinOps platform built around unified cost visibility across AWS, Azure, GCP, and more. For AI cost management specifically, Holori’s approach is grounded in the cloud billing layer: Azure OpenAI costs flow in through the Azure integration, Vertex AI costs through GCP, and Amazon Bedrock costs through AWS. That means AI spend lands in the same platform as the rest of your cloud infrastructure, with the same cost allocation, tagging, anomaly detection, and budget alerting capabilities applied consistently.
The practical advantage is that AI costs don’t live in a separate silo. When your Azure OpenAI spend spikes, you see it in context alongside your other Azure costs, tagged by the same team and project structure you’ve already defined. No separate tool, no separate process.
Where allocation gets more granular, Holori’s virtual tagging system lets you go beyond what cloud providers expose natively. You can define custom allocation rules to attribute AI spend by model, by use case, or by token volume, mapping costs to the teams or products that drove them without requiring changes to your application code or cloud tagging strategy. For organizations running multiple models across multiple teams, that flexibility makes a real difference in the quality of your cost attribution.
Holori does not yet connect directly to the OpenAI or Anthropic billing APIs for organizations using those providers outside of a cloud integration. Most enterprise AI spend flows through Azure OpenAI, Vertex AI, or Bedrock, which covers the majority of use cases, but it’s worth knowing if your teams are calling model APIs directly.
Best for: Engineering and finance teams that want AI costs consolidated into a single multi-cloud FinOps view without managing a separate AI-specific tool.
2. Langfuse
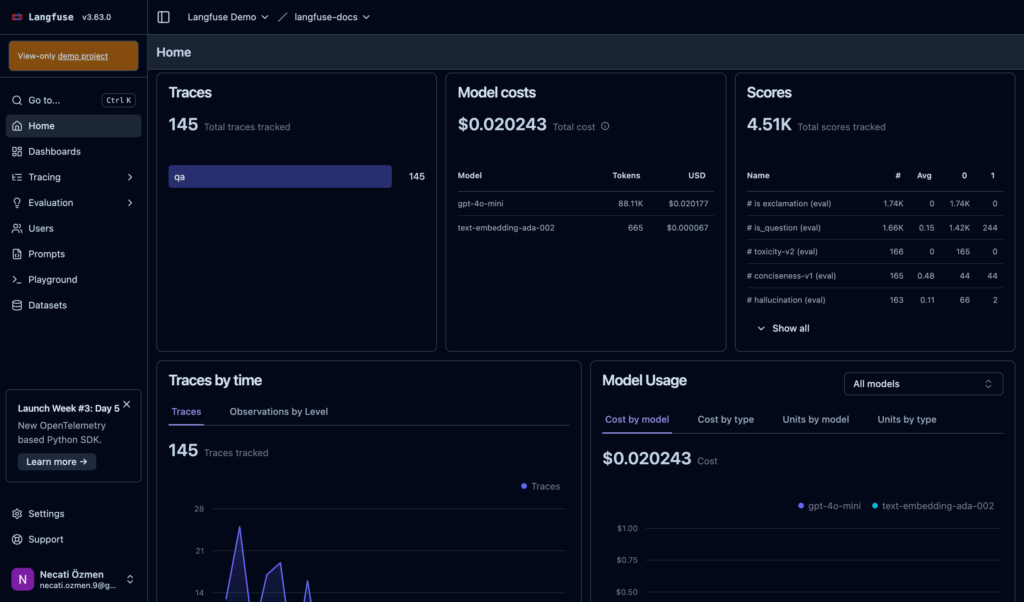
Langfuse is an open-source LLM observability platform that has cost tracking built directly into the tracing layer. Every LLM call is captured as a trace with token counts, model, latency, and cost attached, which means you get attribution at the level of individual requests, users, and sessions rather than at the billing aggregate level.
The key differentiator is that cost data lives alongside quality and performance data in the same platform. You can see not just what a request cost, but whether it was successful, how long it took, and what the inputs and outputs looked like. That combination is genuinely useful for teams trying to understand where AI spend is going and whether it is producing value. It is also self-hostable, which matters for organizations with data residency requirements.
The tradeoff is instrumentation: Langfuse requires your application code to emit traces via its SDK. That is a reasonable ask for greenfield projects, but it adds friction for teams trying to get visibility into existing workloads quickly. It is also primarily an observability tool rather than a FinOps platform, so it lacks the cost allocation, chargeback, and budgeting workflows that finance teams expect.
Best for: Engineering teams that want request-level cost visibility integrated with LLM quality and performance monitoring, and are willing to instrument their application code.
3. LiteLLM
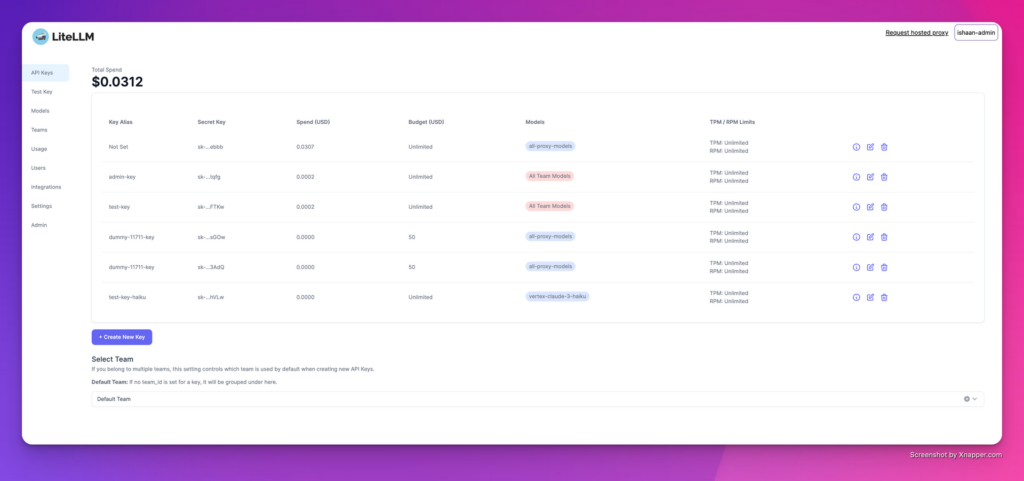
LiteLLM is an open-source proxy that provides a unified interface to over 100 LLM providers behind a single API. Cost tracking is a core feature of the proxy: every request is logged with token counts, model, cost, and latency, and the platform supports budget limits at the user, team, and project level using virtual API keys.
The proxy approach means you get token-level visibility without changing your application logic beyond pointing requests at LiteLLM rather than the provider directly. Budget enforcement is enforced in real time: you can set hard limits that will block requests once a team or user hits their threshold. That is a meaningful operational capability, not just reporting.
LiteLLM is open-source and self-hosted, which gives organizations full control over their data and no per-request SaaS markup. The operational cost of running and maintaining the proxy is the tradeoff, along with the latency overhead inherent in any proxy layer. For teams already thinking about provider abstraction and model routing, the cost tracking capability comes essentially for free.
Best for: Engineering teams that want provider abstraction, model routing, and token-level cost tracking in a single self-hosted layer.
4. WrangleAI
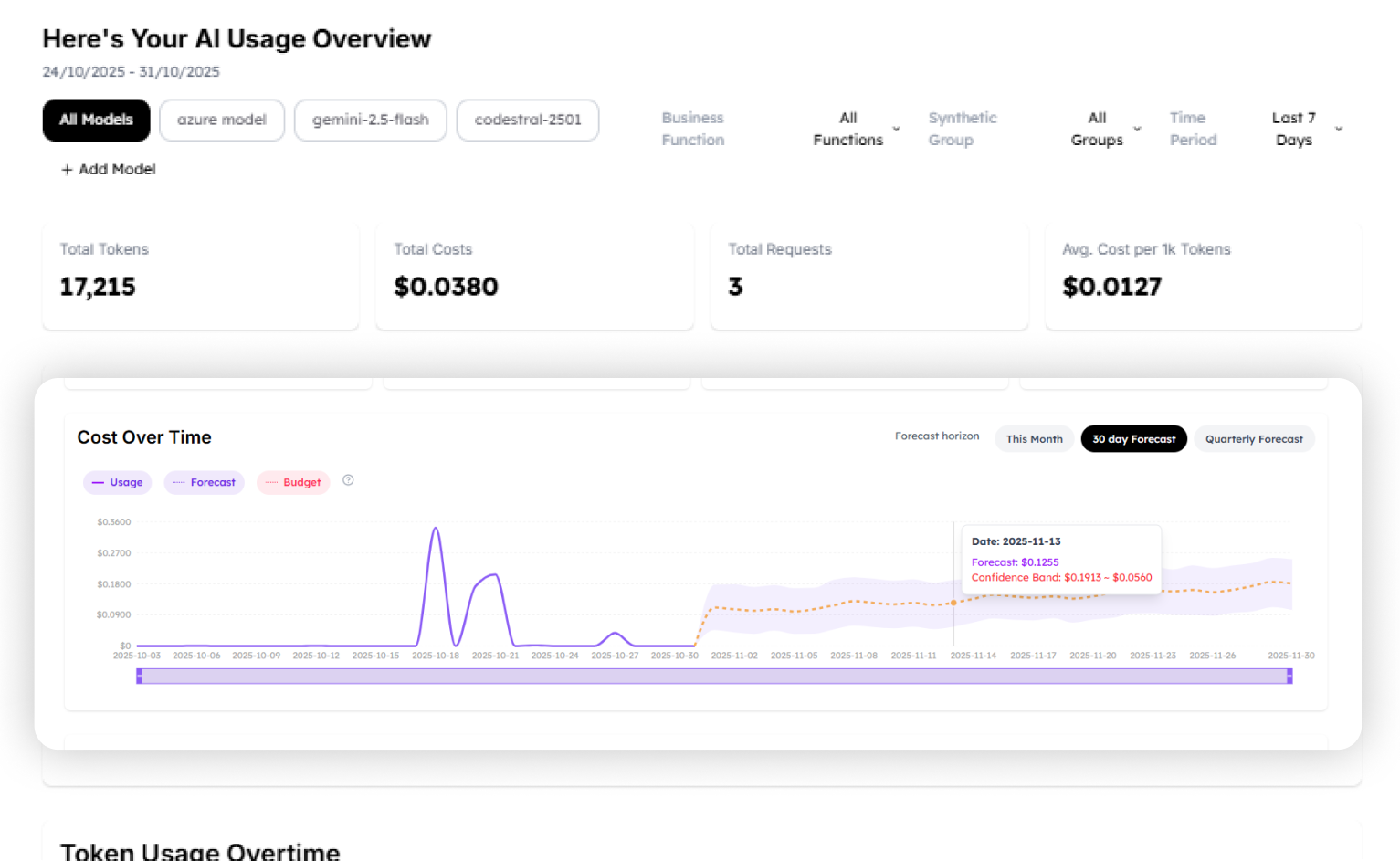
WrangleAI operates as a proxy layer between your applications and the AI model providers. Every API call routes through WrangleAI, which gives it token-level visibility that billing-based tools can’t match: you see exactly how many tokens each request consumed, which model handled it, what it cost, and how long it took.
The platform also does intelligent routing, automatically selecting the most cost-effective model for each request based on task characteristics. That is a meaningful capability: not just showing you where money is going, but actively reducing spend by matching workloads to cheaper models when quality requirements allow it.
The tradeoff is architectural dependency. Introducing a proxy layer into your AI API calls adds latency and creates a critical path dependency. For organizations comfortable with that tradeoff, WrangleAI offers a level of granularity that no billing-based tool can replicate.
Best for: Teams that want token-level visibility and active model routing, and are willing to route API calls through a managed proxy to get it.
5. CloudZero
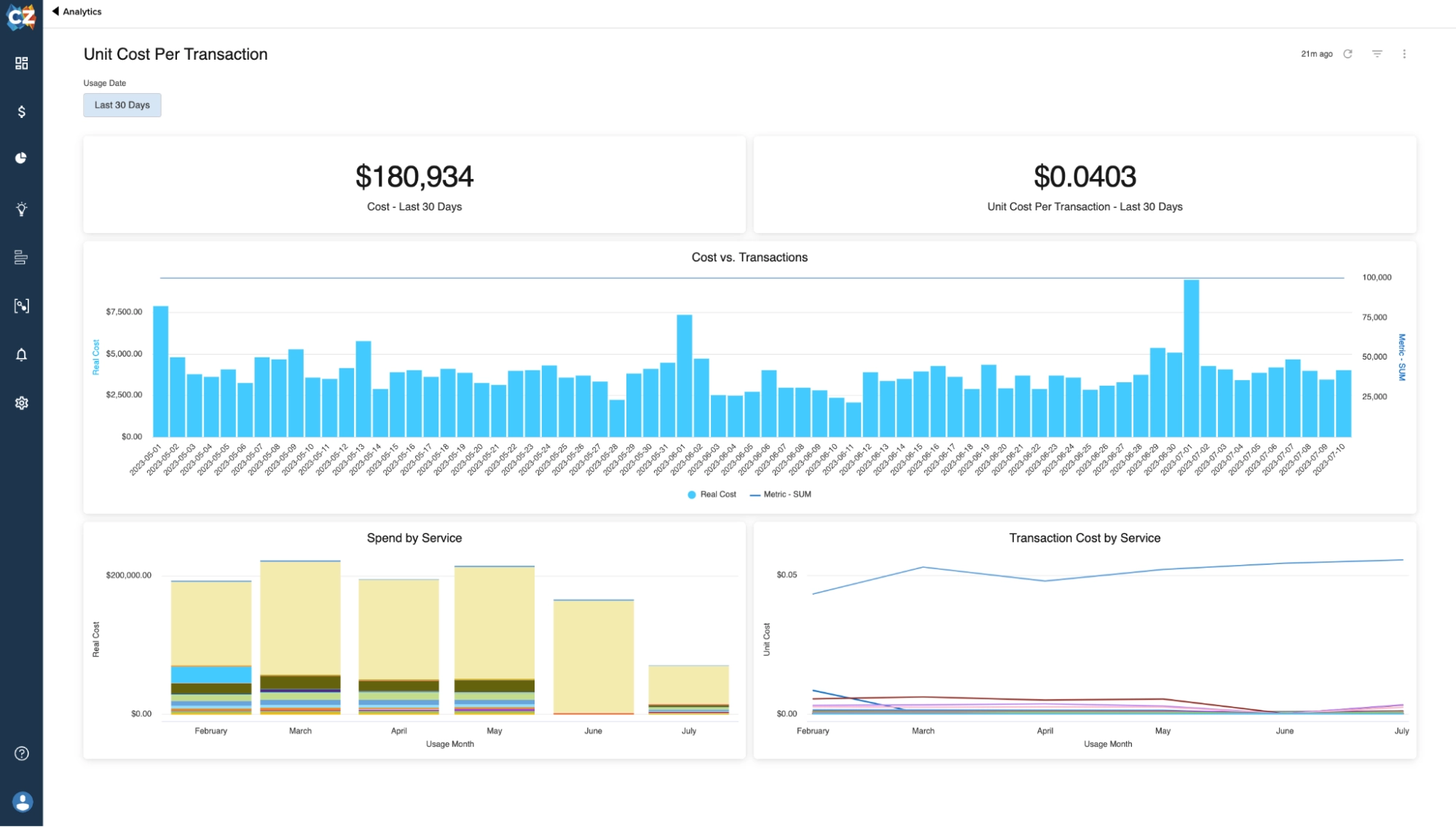
CloudZero focuses on unit cost economics, which is one of the most important and underserved dimensions of AI cost management. Rather than just showing you total spend, CloudZero helps you understand cost per customer, cost per feature, cost per transaction. For AI workloads, that means being able to answer questions like “what does it cost to process one customer query through our AI pipeline?”
That unit economics framing is how mature FinOps organizations think about AI cost efficiency. The platform requires instrumentation via its CostFormation API to map costs to business units at the level of granularity it is known for. The investment pays off in analytical depth, but teams should go in with realistic expectations about the implementation effort.
Best for: Product and engineering teams that want to understand AI cost at the unit economics level and are willing to invest in proper instrumentation.
6. Vantage
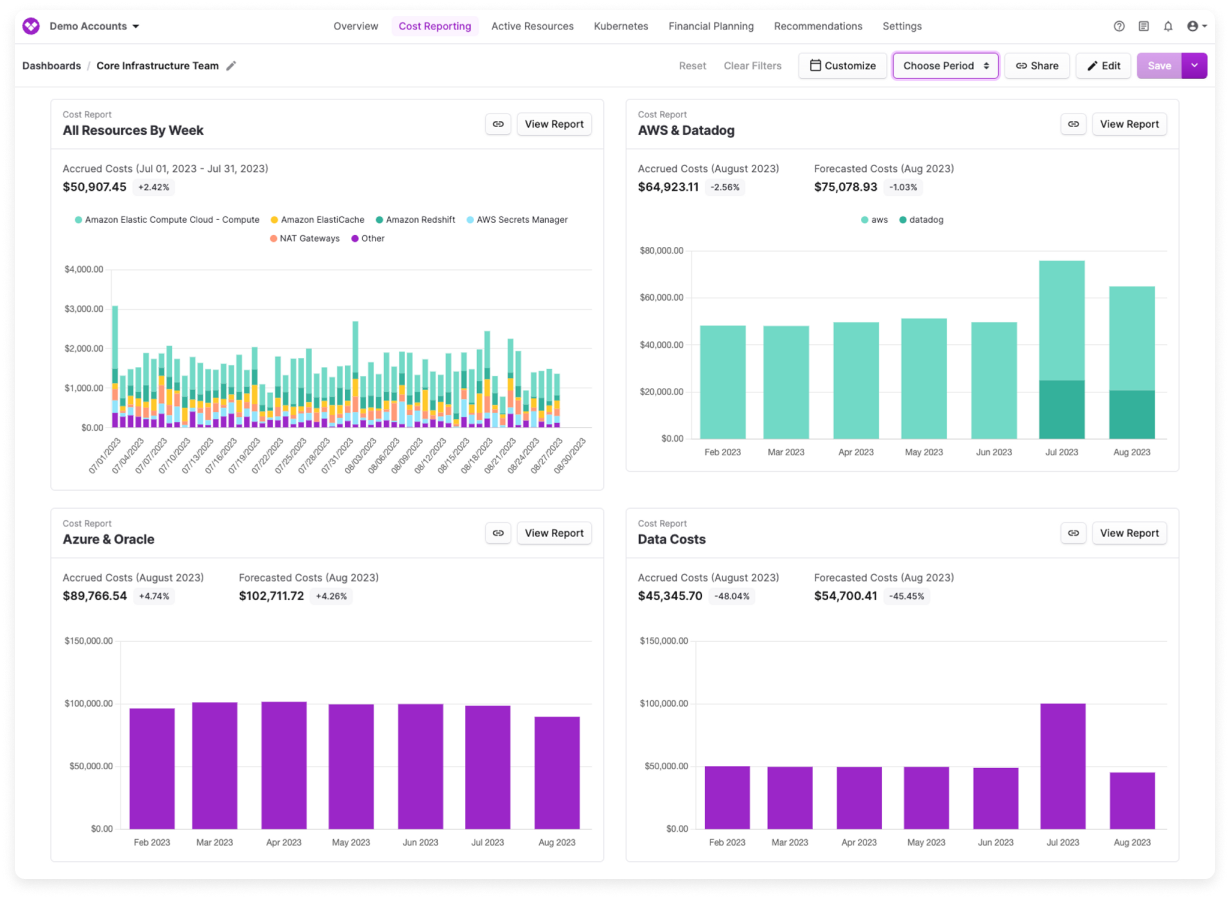
Vantage is one of the most mature independent cloud cost platforms, and it has moved faster than most on AI cost visibility. The platform connects directly to OpenAI and Anthropic billing APIs in addition to the major cloud providers, which gives it broader coverage than tools that rely on cloud-native integrations alone. If your teams are calling model APIs directly and not through a cloud provider, Vantage will catch that spend where others won’t.
The platform offers per-request cost breakdowns, model-level attribution, and cost allocation features that let you map AI spend to teams and projects. It also has good Kubernetes cost visibility, which matters for organizations running self-hosted models or AI infrastructure on containerized workloads.
Best for: Developer-centric teams that need broad AI provider coverage, including direct API integrations with OpenAI and Anthropic.
7. Finout
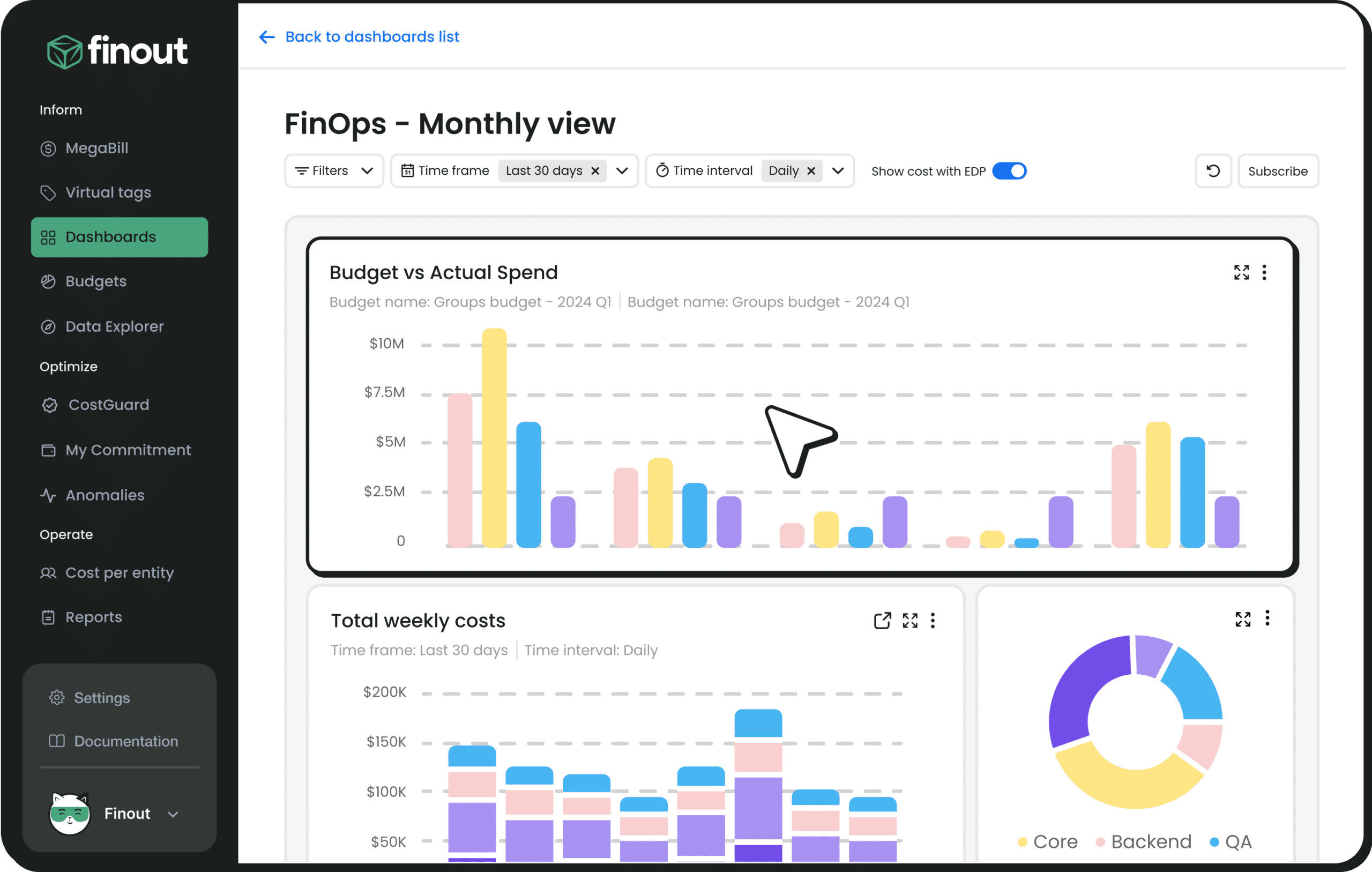
Finout takes a virtual tagging approach that makes it particularly interesting for AI cost attribution. Rather than requiring engineering teams to tag resources at the infrastructure level, Finout lets you define cost allocation rules on top of existing billing data, mapping spend to business units and products without code changes. For AI workloads where instrumentation at the application layer is hard to implement quickly, that flexibility is genuinely useful.
The platform supports major cloud providers and has been building out integrations for AI-specific services. It is strong on the financial reporting and chargeback side, making it a good fit for organizations where FinOps is closely aligned with finance and needs to produce clean cost allocation reports.
Best for: Organizations that need flexible cost attribution without heavy instrumentation, and where FinOps serves a finance reporting function.
8. CAST AI
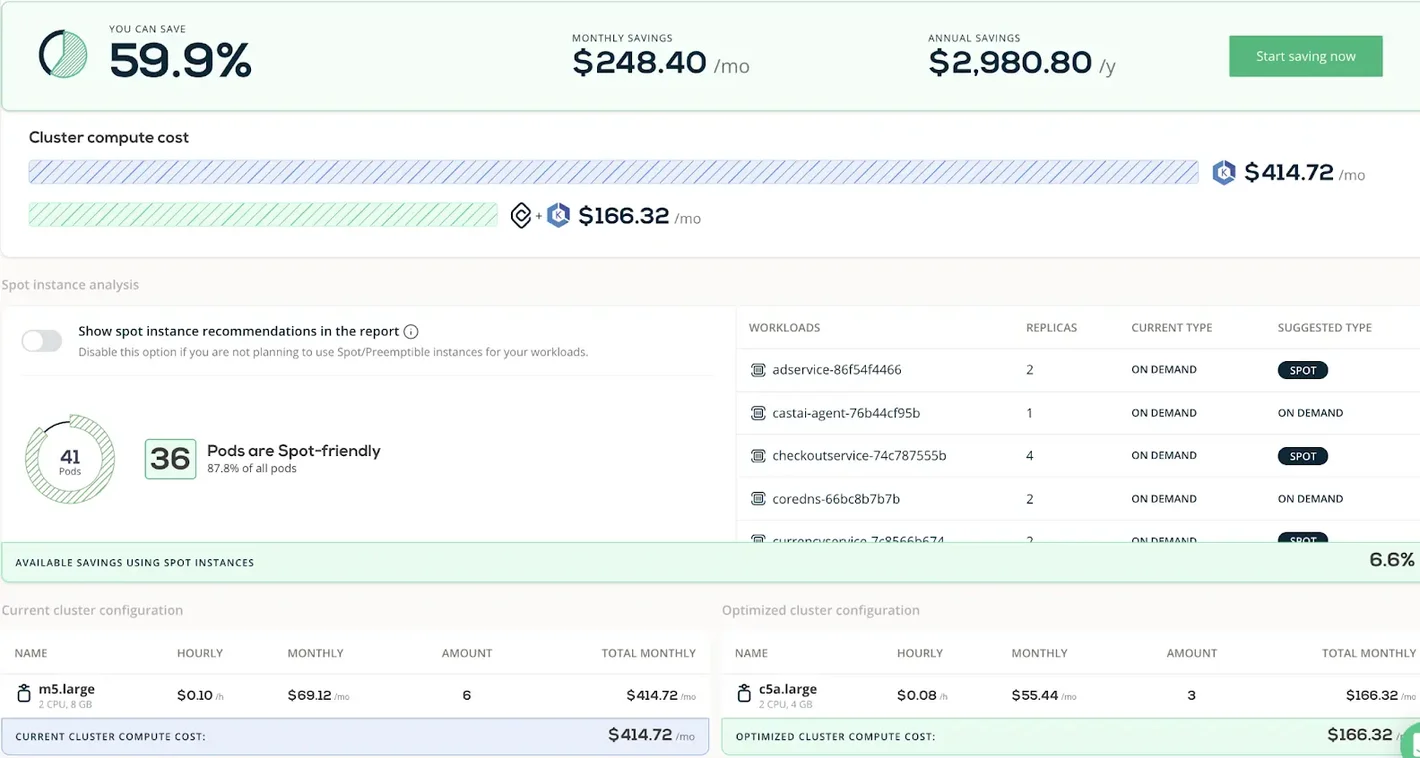
CAST AI is focused on Kubernetes cost optimization, which makes it relevant for organizations running self-hosted AI models, GPU clusters for training, or containerized inference workloads. It does not cover managed AI API services like Azure OpenAI or Bedrock, so it addresses a specific slice of the AI cost picture rather than the full stack.
Within that scope, CAST AI is capable. Its automated optimization can reduce Kubernetes compute costs significantly, and it has built-out support for GPU workload management. For teams running large-scale model training on Kubernetes, it is worth evaluating. For teams primarily consuming managed AI APIs, it is largely not applicable.
Best for: Organizations running AI workloads on Kubernetes who want automated cost optimization for GPU and compute infrastructure.
9. Mavvrik
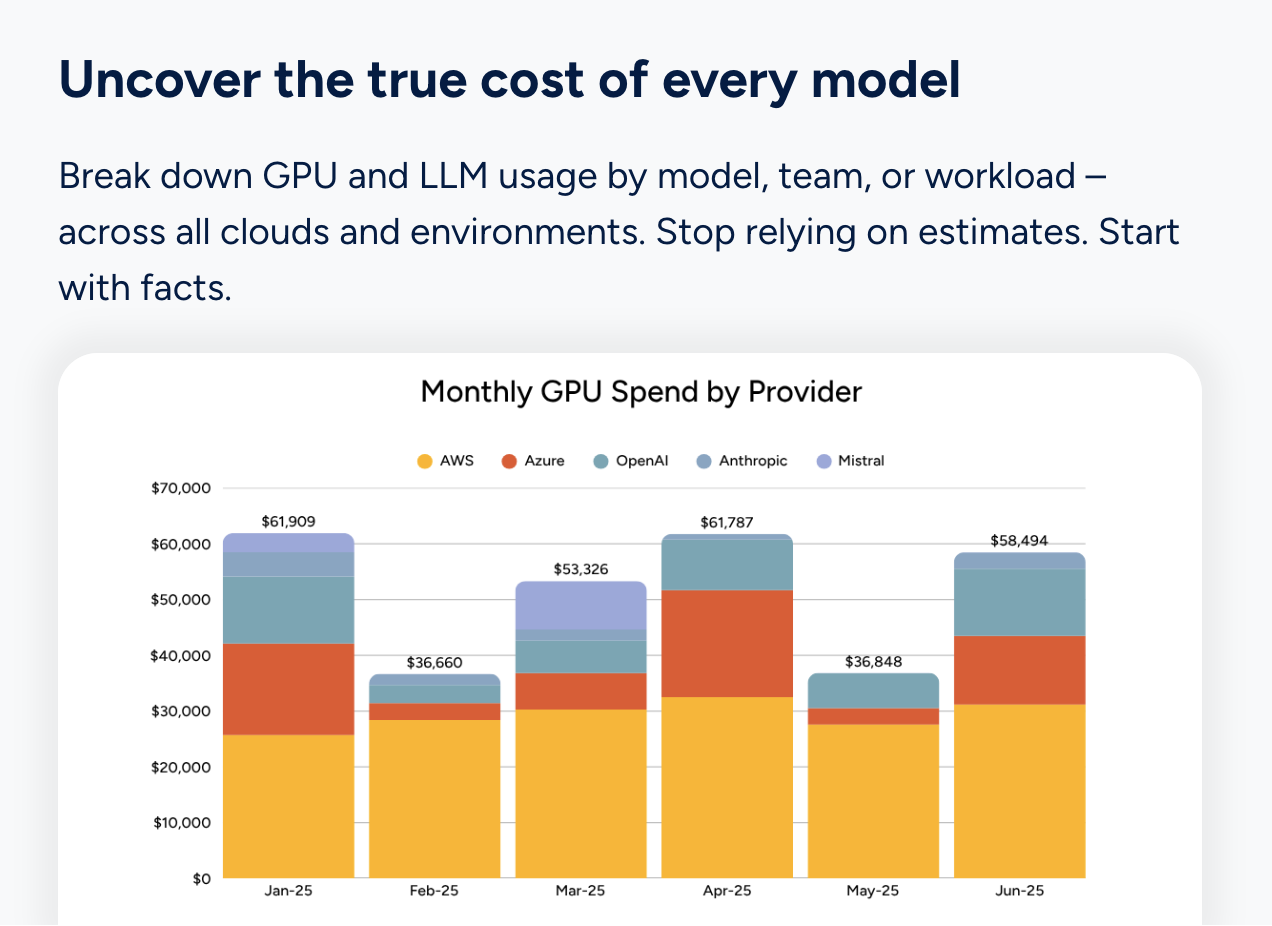
Mavvrik is purpose-built for AI cost management and sits closer to the application layer than traditional FinOps tools. The platform focuses on giving engineering teams granular visibility into AI spend across models and providers, with cost allocation features designed around the way AI workloads are actually structured: by product, feature, and user segment rather than by cloud resource.
The focus on AI-native cost attribution rather than adapting a cloud FinOps model to AI workloads is the right instinct. Teams evaluating Mavvrik should assess how deeply it integrates with their specific provider mix and what the implementation path looks like for their existing infrastructure.
Best for: Teams looking for an AI-native cost management tool built around product and feature-level attribution rather than cloud billing aggregates.
10. Datadog
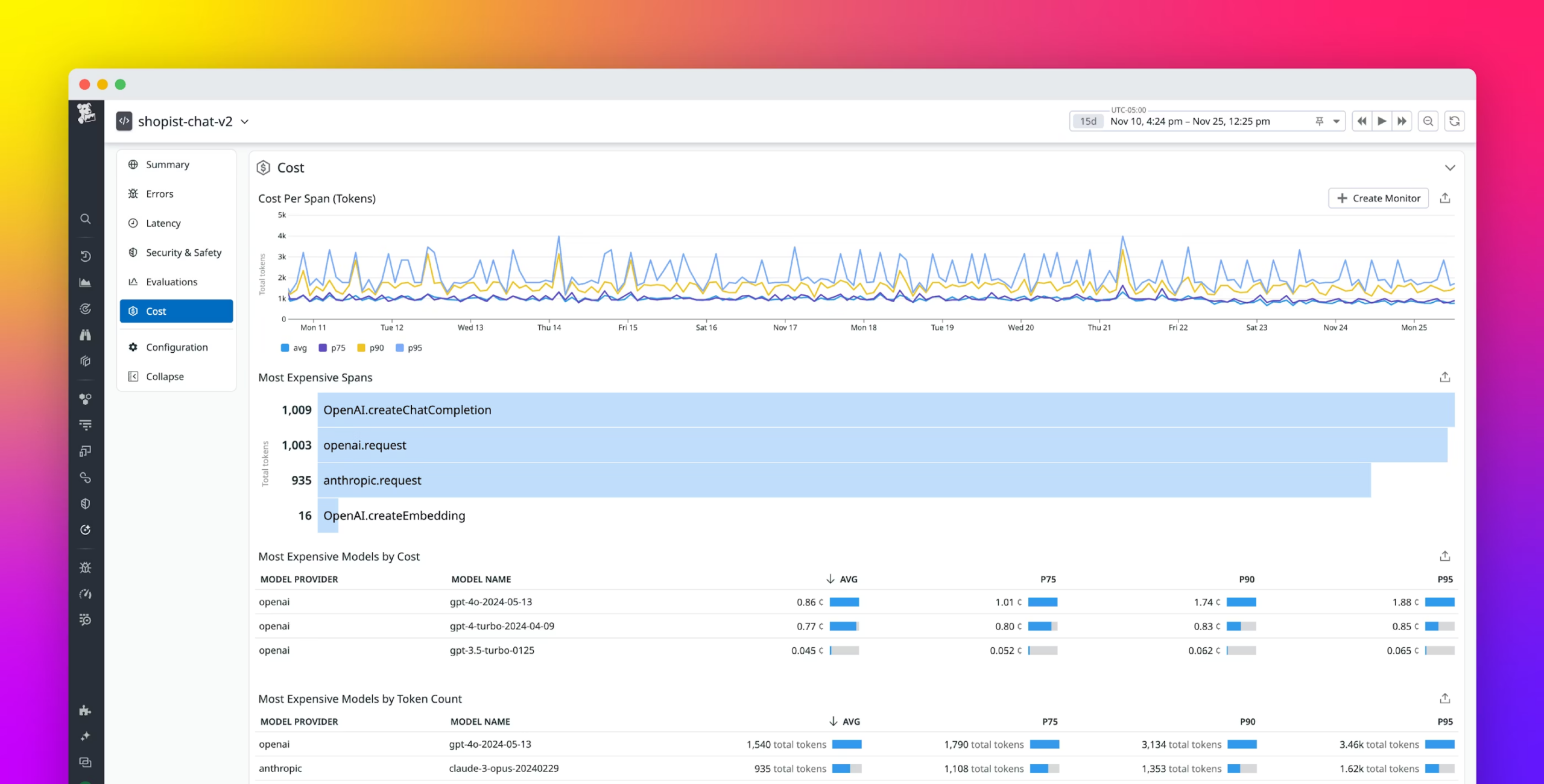
Datadog’s LLM Observability product brings AI cost tracking into the same platform where most engineering teams already monitor their infrastructure and applications. LLM calls are captured as traces with token counts, cost, latency, and quality metrics attached, giving a view of AI spend that is connected to system performance rather than isolated in a billing dashboard.
The advantage is consolidation: if your teams are already running Datadog for APM, infrastructure monitoring, and logs, adding LLM observability does not require introducing another platform. Cost data is directly correlated with the application behavior driving it.
The limitation is that Datadog is an observability platform first. Its cost allocation, chargeback, and budgeting capabilities are not as developed as dedicated FinOps tools, and the pricing model can make it expensive at scale. For organizations where observability and cost are genuinely intertwined problems, the integration is compelling. For those primarily looking for financial governance over AI spend, it may not go far enough.
Best for: Engineering teams already operating within the Datadog ecosystem who want AI cost visibility integrated with application performance monitoring.
How to Choose your next AI cost visibility tool
The right tool depends on where your AI spend actually lives and what questions you need to answer.
If your AI spend flows primarily through cloud-native services (Azure OpenAI, Vertex AI, Bedrock), a multi-cloud FinOps platform like Holori gives you AI cost visibility as part of a unified cloud cost view without adding another tool. If you want token-level visibility through a proxy, WrangleAI or LiteLLM are the two main options, with LiteLLM being self-hosted and open-source and WrangleAI being a managed service. If you want that same depth with LLM quality and performance data in the same place, Langfuse is the strongest option in the observability camp. t.
The worst outcome is treating AI cost visibility as a separate problem from cloud cost management. AI spend is cloud spend. The goal is to have it in the same place, with the same context, analyzed with the same discipline you apply to the rest of your infrastructure.
Holori is a multi-cloud FinOps platform that gives engineering and finance teams unified visibility into cloud spending across AWS, Azure, and GCP, including Azure OpenAI, Vertex AI, and Amazon Bedrock. Request a demo.
FAQ
What is AI cost visibility?
AI cost visibility is the ability to see where your AI spend is going at a useful level of detail — which team, which model, which feature, which request. Total spend figures from your cloud invoice are not visibility. Attribution is.
Do I need a separate tool for AI costs, or can my existing cloud cost platform handle it?
It depends on where your AI spend flows. If your teams are using Azure OpenAI, Vertex AI, or Amazon Bedrock, a multi-cloud FinOps platform that ingests cloud billing data will cover most of what you need. If you are calling OpenAI or Anthropic APIs directly, you will likely need a tool with native integrations to those providers, or a proxy layer that captures usage at the request level.
What is the difference between a billing-based tool and a proxy-based tool?
Billing-based tools pull cost data from your cloud provider invoices after the fact. They are easy to set up but limited in granularity. Proxy-based tools sit between your application and the model provider, capturing every request in real time. They give you token-level detail and can enforce budgets live, but they introduce latency and an architectural dependency.
What are unit economics for AI, and why do they matter?
Unit economics means understanding cost per meaningful business outcome: cost per user query, cost per document processed, cost per customer. Total spend tells you how much you are spending. Unit economics tells you whether that spend is sustainable as you scale. A feature that costs $0.002 per query is very different from one that costs $0.20, even if both look small in absolute terms today.
How should I allocate AI costs across teams and products?
The most reliable method is tagging at the infrastructure or API key level before costs are incurred. Virtual tagging tools like Finout can apply allocation rules after the fact if you are starting without a tagging strategy. For the highest granularity, proxy-based tools or SDK instrumentation let you attach cost to specific features and user segments directly in application code.
Is open-source tooling production-ready for AI cost management?
Yes, for the right use cases. LiteLLM and Langfuse are both actively maintained, widely adopted, and production-ready. The tradeoff is operational overhead: you are responsible for hosting, scaling, and maintaining them. For teams with the engineering capacity, the control and cost savings are worth it. For teams that want a managed service, the commercial options on this list are the better fit.