Building advanced generative AI applications is made simpler with AWS Bedrock, a fully managed, serverless AI service. Bedrock provides access to high-performance foundation models (FMs) from leading providers like Amazon Titan, Anthropic, Mistral and Stability AI. Its serverless architecture automatically scales, allowing developers to focus on application development while AWS handles infrastructure. However, managing costs effectively requires understanding Bedrock’s pricing models and optimizing usage.
What is AWS Bedrock ?
AWS Bedrock is Amazon Web Services’ serverless AI service that gives developers access to state-of-the-art foundation models (FMs) from premier providers, including Amazon Titan, Anthropic, Mistral AI, Meta AI, Stability AI, and others. Designed to simplify machine learning integration for businesses, Bedrock allows users to leverage pre-trained models across a variety of applications, including natural language processing (NLP), image generation, virtual assistants and data analysis, without the need to build or maintain complex AI infrastructure.
Bedrock provides a flexible, plug-and-play approach to machine learning. Developers can select from an array of pre-trained foundation models, each optimized for different tasks, such as text summarization, sentiment analysis, and content generation. For companies requiring a custom touch, Bedrock also enables model fine-tuning on proprietary data, allowing businesses to tailor the model’s responses or outputs to align with specific industry requirements or brand tone.
A unique benefit of AWS Bedrock is its serverless architecture, which automatically scales resources based on demand and charges users only for the model usage. This elasticity is particularly valuable for handling workloads with variable AI demands, ensuring optimal performance during peak times without the hassle or expense of manual resource scaling. Bedrock also seamlessly integrates with other AWS services, such as S3 for storage, Lambda for event-based functions or Sagemaker enhancing its capability for end-to-end machine learning workflows.
Azure OpenAI vs AWS Bedrock
In contrast, Azure OpenAI Service focuses specifically on models developed by OpenAI, including GPT, Codex, and DALL-E. It provides deep integration with Microsoft’s Azure ecosystem, allowing companies to securely run OpenAI models while leveraging Azure’s security, compliance, and identity services. Azure OpenAI is especially beneficial for enterprises that are committed to the Microsoft ecosystem, as it provides a tightly integrated experience with Azure tools like Azure Cognitive Services, enabling seamless data integration and management.
In summary, AWS Bedrock offers a broader selection of foundation models and a serverless infrastructure ideal for multi-model use, while Azure OpenAI provides specialized access to OpenAI models with robust integration within Azure’s ecosystem, ideal for enterprises invested in Microsoft’s cloud and compliance offerings.
AWS Bedrock Pricing Models
Here’s a quick summary table comparing AWS Bedrock On-Demand, Provisioned Throughput and Batch pricing models:
| Feature | AWS Bedrock On-Demand | AWS Bedrock Provisioned Throughput | AWS Bedrock Batch |
|---|---|---|---|
| Use Case | Variable or unpredictable workloads | Large, consistent workloads needing guaranteed performance | Large-scale, one-time or periodic batch processing |
| Pricing | Pay-per-use, charged per token processed | Hourly rate based on reserved model units | Discounted rate per token for supported models |
| Throughput | Scales dynamically with demand | Guaranteed throughput with dedicated model units | Processes multiple prompts in a single input file for efficient high-volume processing |
| Custom Model Access | Not available | Required for using custom models | Limited; custom models may not be supported |
| Commitment Terms | None | 1-month or 6-month commitments | None |
| Ideal For | Ad hoc analysis, exploratory or variable workloads | Production applications with predictable, high-demand usage | Bulk data processing, cost-efficient handling of large datasets |
Pricing for Bedrock is based on usage and can vary by workload. Here’s a breakdown of the main pricing options:
On-Demand Pricing
With the On-Demand pricing model in AWS Bedrock, you’re billed solely based on your actual usage, with no need for upfront or time-based commitments. This model charges per token or per image generated, depending on the type of AI model you’re using.
- Text-Generation Models: For text-based models, costs are calculated by the number of tokens processed. Charges apply to both input tokens (what the model processes from user input) and output tokens (what the model generates in response). A token, which represents a small chunk of text such as a few characters or a word segment, is the core unit of cost. This granular approach allows costs to closely match usage, making it a flexible choice for variable workloads.
- Embeddings Models: With embeddings models, pricing is based only on the number of input tokens. This means costs are limited to the text data you input for generating vector embeddings, useful in search and recommendation engines.
- Image-Generation Models: For image models, charges apply per image generated. This straightforward billing method makes it easy to estimate costs based on the number of images needed.
Cross-Region Inference: On-demand pricing also supports cross-region inference for select models, enabling you to manage bursts of traffic and ensure higher throughput by spreading processing across AWS regions. This allows for resilient, scalable operations across multiple regions at no additional cost, as charges remain based on the pricing rates of the originating (source) region.
This model provides significant flexibility, as you’re billed only for resources used without committing to specific usage volumes or time frames, making it ideal for unpredictable or dynamic workloads.
On-demand example (text generation):
Imagine you’re using AWS Bedrock to power a product recommendation chatbot during peak shopping hours. Here’s a breakdown of potential costs:
- Token Usage: Each user query uses 50 input tokens, and the response generates around 200 output tokens.
- Rates: Input tokens cost $0.001 per 1,000 tokens, and output tokens cost $0.003 per 1,000 tokens.
- Usage Volume: The chatbot processes 2,000 queries daily, which translates to 100,000 input tokens and 400,000 output tokens each day.
Daily Cost Calculation:
- Input Cost: 100,000 tokens / 1,000 × $0.001 = $0.10 per day
- Output Cost: 400,000 tokens / 1,000 × $0.003 = $1.20 per day
- Total Daily Cost: $0.10 + $1.20 = $1.30 per day
- Estimated Monthly Cost: $1.30 × 30 = $39 per month
This on-demand model offers flexibility, only charging for the actual tokens processed.making it ideal for dynamic workloads.

Provisioned Throughput Pricing
AWS Bedrock’s Provisioned Throughput mode is a pricing model that offers dedicated capacity for organizations with consistent, large-scale inference workloads requiring guaranteed performance. In this mode, companies purchase model units for a specific foundation or custom model, each providing a defined throughput measured in tokens per minute. Tokens represent units of text processed, such as input or output tokens, so a higher number of tokens translates to handling larger or more complex data inputs at a faster rate.
This model is particularly useful for production-grade AI applications with predictable usage patterns, as it allows companies to reserve throughput capacity that ensures models can handle constant workloads without interruptions. This reserved capacity benefits organizations needing low-latency and reliable performance for tasks like customer support, content generation, and real-time data analysis.
- Guaranteed Throughput: Model units provide a set rate of throughput, helping companies meet service-level agreements for applications that need consistent performance.
- Custom Model Access: Custom-trained models are exclusively accessible through Provisioned Throughput, making it essential for businesses that require specialized or fine-tuned models.
- Hourly Pricing with Flexible Terms: Organizations are charged hourly based on the number of model units reserved, and they can choose from 1-month or 6-month commitment terms, depending on their forecasted usage and budget preferences. The longer commitment terms typically offer cost advantages.
Overall, AWS Bedrock’s Provisioned Throughput model is a robust solution for companies with large, predictable AI workloads. It combines predictable pricing with guaranteed performance, making it well-suited for enterprise applications requiring dependable, scalable AI processing.
Provisioned Throughput Pricing example
Let’s go through an example calculation for AWS Bedrock Provisioned Throughput pricing.
Suppose a business requires consistent, high-throughput access to a model, and it decides to reserve 5 model units for a custom model. Each model unit provides a set number of tokens per minute, and pricing is based on an hourly rate per model unit.
Let’s assume:
- Each model unit costs $0.50 per hour.
- The business opts for a 1-month commitment (around 730 hours in a month).
- Hourly Cost for Model Units:
- 5 model units × $0.50/hour = $2.50 per hour
- Monthly Cost:
- $2.50/hour × 730 hours = $1,825 per month
Batch processing
With batch processing, you can submit multiple prompts in a single input file, making it an efficient way to process large datasets all at once. The pricing model for batch processing is similar to on-demand, but with a key advantage: you can often receive a 50% discount on supported foundation models (FMs) compared to the on-demand rate.
This discount is a great way to reduce costs, but keep in mind that batch processing isn’t available for all models. Check the official documentation for a list of supported models.
Model Customization
Bedrock enables model customization through fine-tuning with proprietary data. Customization costs depend on the number of tokens processed and a monthly storage fee for the customized model, making it a powerful option for tailored AI applications.
Model Evaluation
For testing different models without large-scale usage, model evaluation pricing allows you to pay based on token use, ideal for early-stage projects or comparing model performance.
AWS Bedrock Pricing depends on the model used and providers
Amazon Bedrock provides access to a curated selection of foundation models (FMs) from top AI providers, including Anthropic, Meta or Mistral AI. The price depends on each AI provider and location.
Let’s see the cost In N. Virginia for Anthropic, Meta and Mistral AI. If you want to see more additional prices from other AI providers check here.
Anthropic
Anthropic models focus on safe and aligned AI, emphasizing responsible language processing with robust guardrails for user interaction.
On-Demand and Batch pricing – Region: US East (N. Virginia) and US West (Oregon)
| Anthropic models | Price per 1,000 input tokens | Price per 1,000 output tokens | Price per 1,000 input tokens (batch) | Price per 1,000 output tokens (batch) |
| Claude 3.5 Sonnet** | $0.003 | $0.015 | $0.0015 | $0.0075 |
| Claude 3.5 Haiku | $0.001 | $0.005 | $0.0005 | $0.0025 |
| Claude 3 Opus* | $0.015 | $0.075 | $0.0075 | $0.0375 |
| Claude 3 Haiku | $0.00025 | $0.00125 | $0.000125 | $0.000625 |
| Claude 3 Sonnet | $0.003 | $0.015 | $0.0015 | $0.0075 |
| Claude 2.1 | $0.008 | $0.024 | N/A | N/A |
| Claude 2.0 | $0.008 | $0.024 | N/A | N/A |
| Claude Instant | $0.0008 | $0.0024 | N/A | N/A |
Provisioned Throughput pricing – Region: US East (N. Virginia) and US West (Oregon)
| Anthropic models | Price per hour per model with no commitment | Price per hour per model unit for 1-month commitment | Price per hour per model unit for 6-month commitment |
| Claude Instant | $44.00 | $39.60 | $22.00 |
| Claude 2.0/2.1 | $70.00 | $63.00 | $35.00 |
Meta Llama
Meta LLaMA is a high-performance language model developed by Meta, designed for natural language understanding and generation tasks at scale.
Llama 3.2
On-Demand and Batch pricing – Region:US East (N. Virginia)
| Meta models | Price per 1,000 input tokens | Price per 1,000 output tokens | Price per 1,000 input tokens (batch) | Price per 1,000 output tokens (batch) |
|---|---|---|---|---|
| Llama 3.2 Instruct (1B) | $0.0001 | $0.0001 | N/A | N/A |
| Llama 3.2 Instruct (3B) | $0.00015 | $0.00015 | N/A | N/A |
| Llama 3.2 Instruct (11B) | $0.00035 | $0.00035 | N/A | N/A |
| Llama 3.2 Instruct (90B) | $0.002 | $0.002 | N/A | N/A |
Provisioned Throughput pricing – Region:US West (Oregon)
| Meta models | Price per hour per model unit for no commitment | Price per hour per model unit for 1-month commitment | Price per hour per model unit for 6-month commitment |
|---|---|---|---|
| Llama 3.1 Instruct (8B) | $24.00 | $21.18 | $13.08 |
| Llama 3.1 Instruct (70B) | $24.00 | $21.18 | $13.08 |
Mistral AI
Mistral AI offers cutting-edge language models optimized for various NLP tasks, delivering high accuracy and efficiency in data processing and comprehension.
On-Demand and Batch pricing – Region:US East (N. Virginia)
| Mistral models | Price per 1,000 input tokens | Price per 1,000 output tokens | Price per 1,000 input tokens (batch) | Price per 1,000 output tokens (batch) |
|---|---|---|---|---|
| Mistral 7B | $0.00015 | $0.0002 | N/A | N/A |
| Mixtral 8*7B | $0.00045 | $0.0007 | N/A | N/A |
| Mistral Small (24.02) | $0.001 | $0.003 | $0.0005 | $0.0015 |
| Mistral Large (24.02) | $0.004 | $0.012 | N/A | N/A |
Cost Optimization Strategies for AWS Bedrock
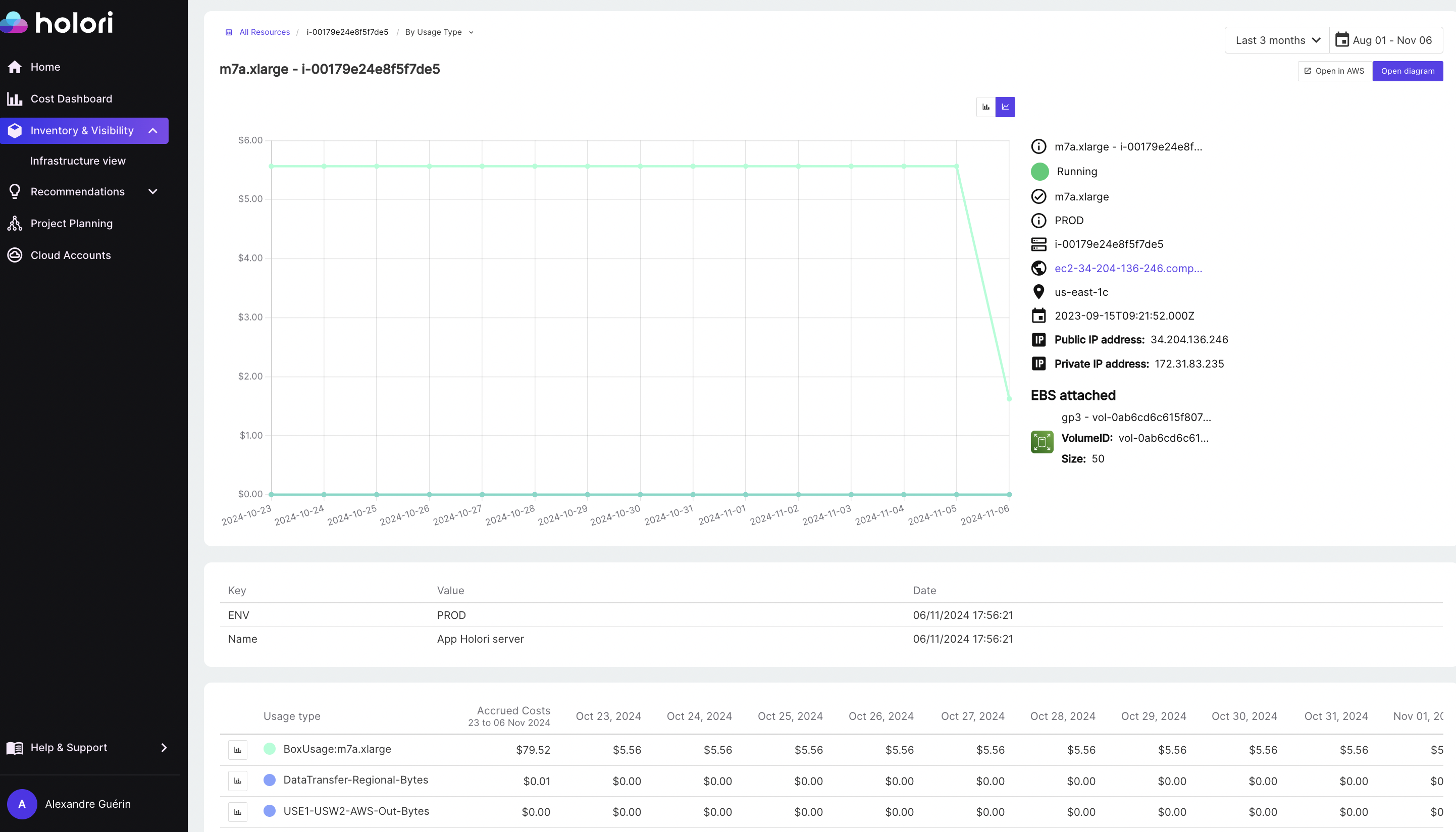
Monitor Your Workloads Efficiently
AWS CloudWatch offers real-time monitoring of key metrics, such as token usage and model activity, helping you stay on top of Bedrock costs with alerts when thresholds are reached. For further tracking, AWS CloudTrail’s audit trail provides insights into resource usage by team, allowing you to pinpoint spending patterns. Additionally, tools like Holori FinOps platform can complement this monitoring by consolidating cost data across providers, making it easier to assess and manage AWS Bedrock expenses alongside other cloud services.
Optimize Model Selection and the right AI provider
Comparing the pricing of different AI model providers within AWS Bedrock can reveal significant cost-saving opportunities. Each foundation model—whether from Meta, Anthropic, Mistral AI, or Amazon—has its own pricing structure and performance attributes, which means the cost-effectiveness of a model can vary based on the workload. By benchmarking these models against each other for specific tasks, such as sentiment analysis or summarization, you can identify options that offer the best balance of performance and cost.
Utilize Reserved Capacity for Large Workloads
For steady, large-scale workloads, reserved capacity can be a more cost-effective option than on-demand pricing. Provisioned throughput allows you to secure lower rates, but it’s best to monitor initial usage patterns with tools like Holori before committing to ensure that reserved capacity delivers real savings based on your workload demands.
Leverage Batch Processing
When working with extensive datasets, batch processing can yield considerable cost savings. Use cases like sentiment analysis and data translation benefit from this approach, as batch processing enables you to handle bulk data at a discounted rate compared to on-demand usage, optimizing costs for high-volume tasks.
Tag Resources and Use AWS Cost Categories
Tagging Bedrock resources by project or team is a simple way to track costs more accurately. Combined with AWS Cost Categories, which organize expenses into custom groups, tagging provides a clearer view of spending across departments or projects, making it easier to analyze, allocate, and optimize costs organization-wide.
How Holori’s FinOps Platform Can Help ?
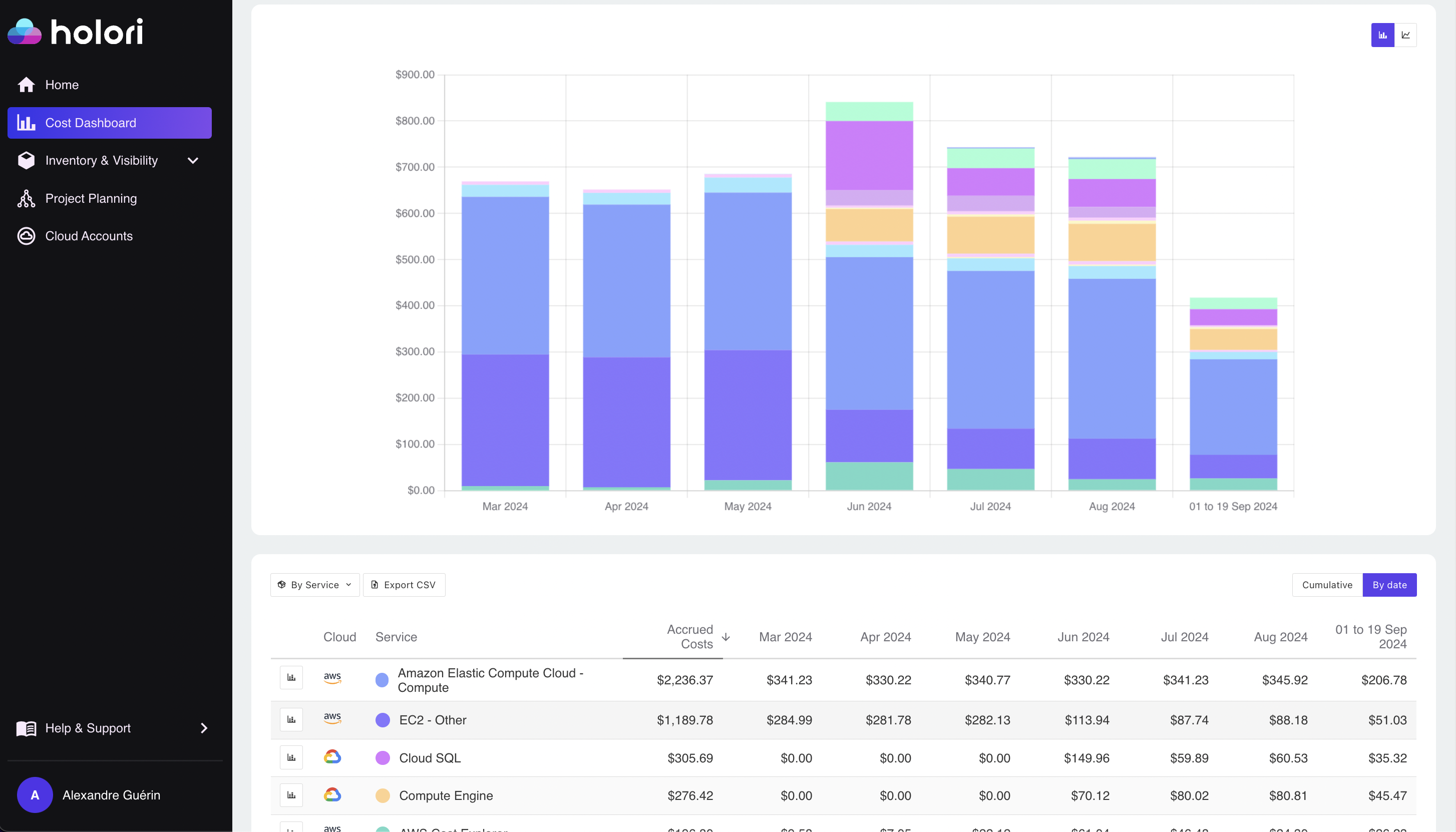
Holori’s FinOps platform simplifies cost management for AWS Bedrock by providing a centralized view of your cloud spending. With Holori, you can monitor and compare expenses across multiple providers, gaining insights into how different AI models impact your overall budget. The platform’s intuitive dashboards allow you to track spending by project, team, or department, making it easy to identify high-cost areas and optimize resource allocation. Holori’s Virtual Tags and automated infrastructure diagrams further enhance your ability to maintain consistent tagging policies and visualize model configurations, while real-time alerts keep you informed of any cost anomalies. These features make Holori a powerful tool for managing Bedrock expenses, helping teams to optimize both budget and performance in their AI workloads.
Conclusion
AWS Bedrock empowers developers to create advanced generative AI applications by providing seamless access to high-performance foundation models from providers like Amazon Titan, Anthropic, and Stability AI. With its serverless, scalable architecture, Bedrock simplifies the integration of AI models into business workflows without the overhead of managing infrastructure. However, achieving cost efficiency with AWS Bedrock requires a clear understanding of its diverse pricing models and the ability to optimize usage based on specific workload needs.
By leveraging cost-effective strategies such as model benchmarking, batch processing, and reserved capacity, companies can maximize the value of AWS Bedrock while controlling costs. Tools like Holori’s FinOps platform further enhance this cost management, offering insights into cloud spend and allowing teams to monitor AI model expenses across projects. AWS Bedrock thus provides a robust and flexible platform for AI innovation, empowering businesses to harness AI’s potential while keeping cloud spending in check.
Visualize and optimize your AWS cloud costs now : https://app.holori.com/